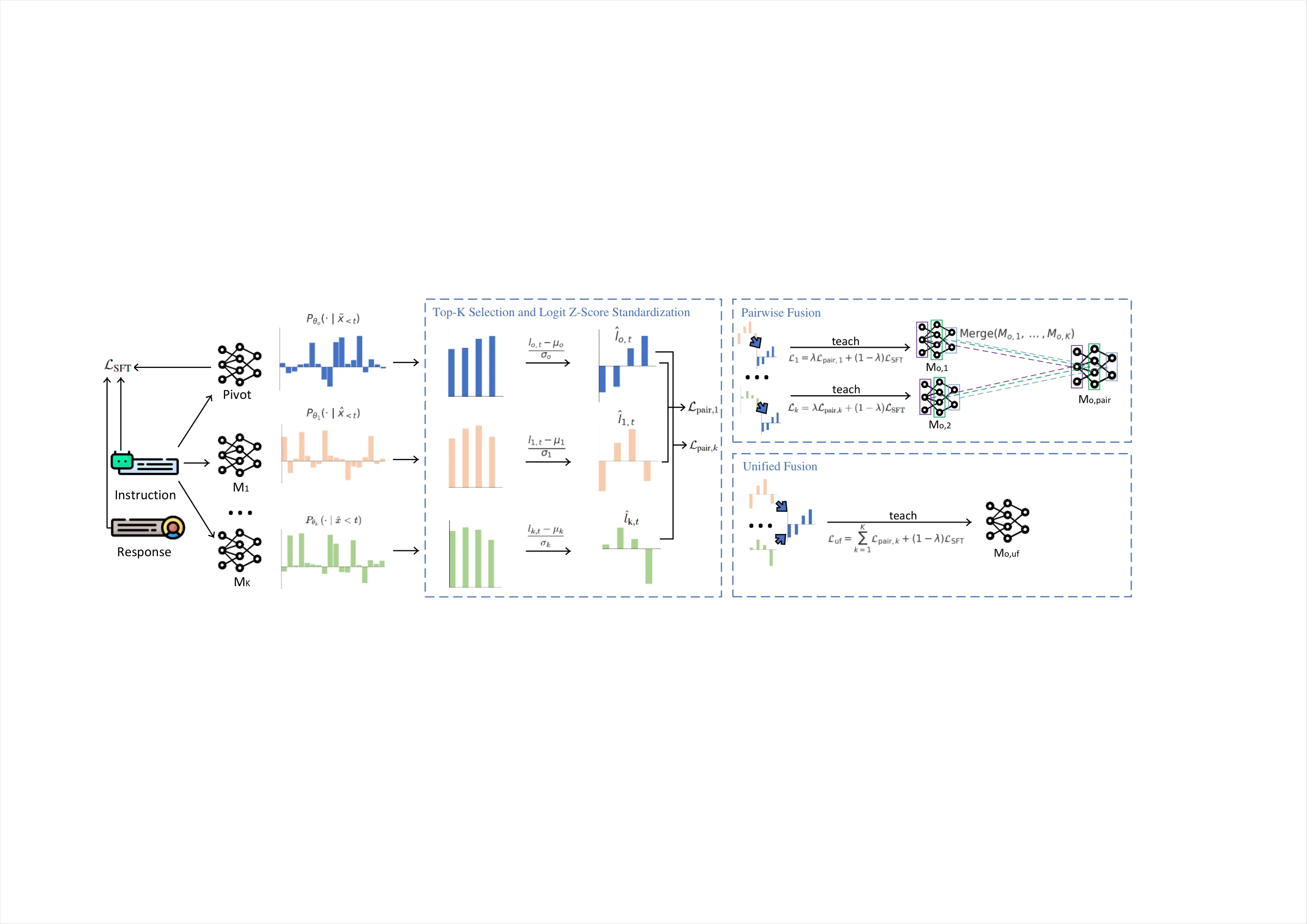
InfiFusion: A Unified Framework for Enhanced Cross-Model Reasoning via LLM Fusion
ABSTRACT
We introduce InfiFusion, an efficient training pipeline designed to integrate multiple domain-specialized Large Language Models (LLMs) into a single pivot model, effectively harnessing the strengths of each source model. InfiFusion overcomes limitations by enhancing Universal Logit Distillation (ULD) with Top-K selection and Logits Standardization. We propose two fusion strategies: Pairwise Fusion and Unified Fusion. InfiFusion outperforms the state-of-the-art models across 11 widely applied benchmarks while significantly reducing computational costs to only 160 H800 GPU hours compared to the millions typically required for traditional LLM training.
Abstract
We introduce InfiFusion, an efficient training pipeline designed to integrate multiple domain-specialized Large Language Models (LLMs) into a single pivot model, effectively harnessing the strengths of each source model. Traditional fusion methods either merge model parameters directly or rely on knowledge distillation with rigid assumptions, limiting their flexibility and efficiency. InfiFusion overcomes these limitations by enhancing Universal Logit Distillation (ULD) with Top-K selection and Logits Standardization. Top-K selection reduces noise by prioritizing the most informative logits, while logits standardization ensures better alignment between models by normalizing logits across diverse models. We propose two fusion strategies: Pairwise Fusion (InfiFusion), where each source model's knowledge is distilled individually into the pivot model followed by merging and Unified Fusion (InfiFusion), where knowledge from all source models is distilled simultaneously into the pivot model. InfiFusion outperforms the state-of-the-art models, such as Qwen-2.5-14B-Instruct and Phi-4, across 11 widely applied benchmarks covering reasoning, coding, mathematics, and instruction-following tasks. Notably, InfiFusion achieves this superior performance while significantly reduces computational costs, completing full training with only 160 H800 GPU hours compared to the millions typically required for traditional LLM training.
Introduction
Large Language Models (LLMs) have demonstrated remarkable success across various tasks such as general reasoning, mathematics, programming, and scientific applications. However, no single model excels in all domains, and training a comprehensive model from scratch requires significant computational resources. An alternative approach is to fuse multiple domain-specialized models into a single pivot model, combining their strengths without requiring retraining a monolithic model.
Traditional LLM merging techniques rely on direct integration of model parameters, but these methods presuppose uniform architectures across models and often fail to capture the strengths of diverse specialized models. LLM fusion typically transfers expertise from source models to the pivot model via knowledge distillation, supporting models with varying architectures and vocabularies. However, the performance is strongly dependent on vocabulary and token alignment, limiting their applicability. The Universal Logit Distillation (ULD) framework addresses this by using the 1-Wasserstein distance to align token distributions across models with different vocabularies. Despite its potential, ULD faces challenges, like zero-padding noise and inefficiencies in large-scale models.
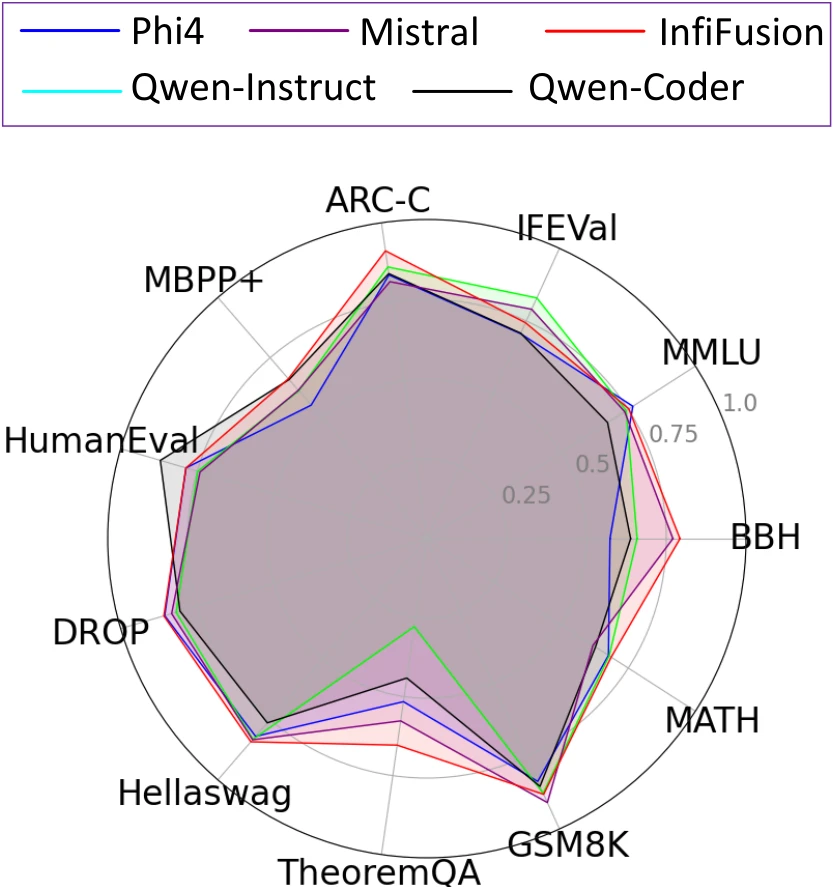
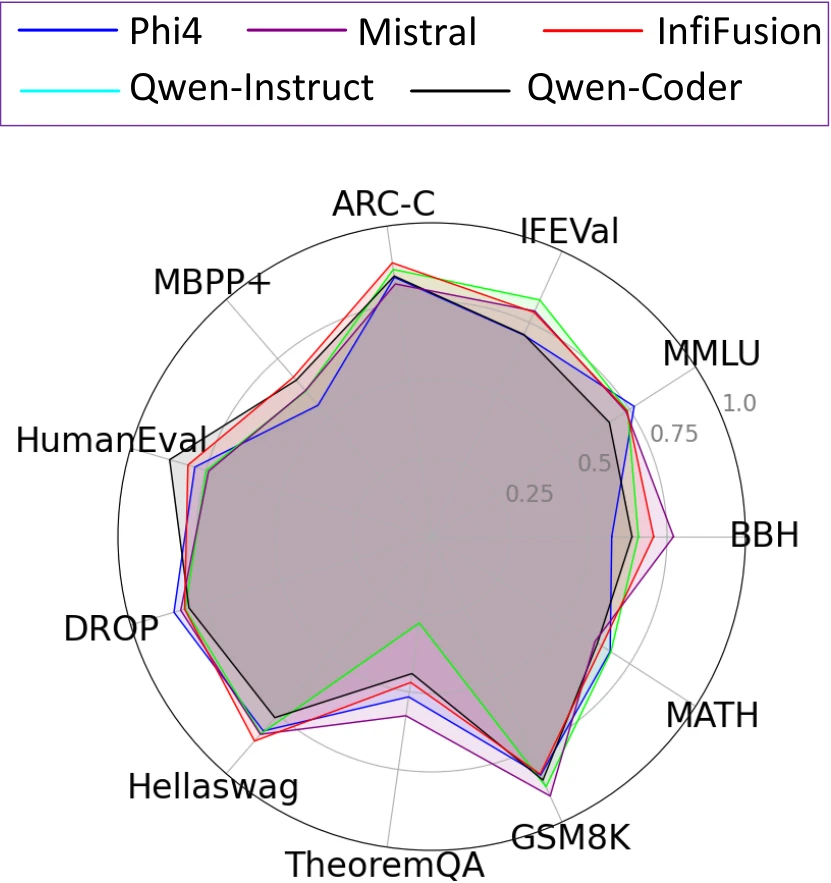
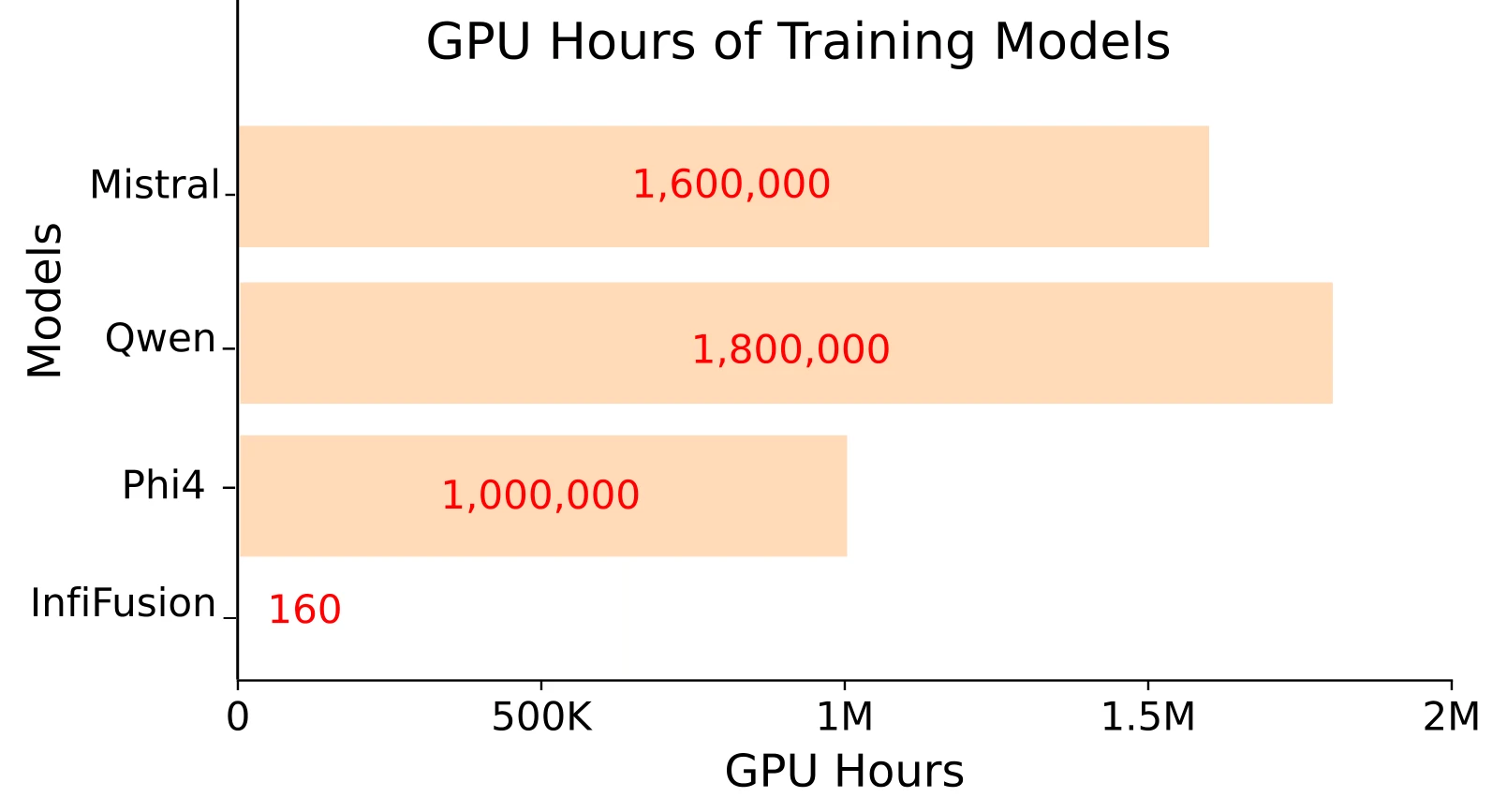
Figure 1: Performance of InfiFusion on the pivot models Phi-4 and Qwen2.5-14B-Instruct. In all cases, InfiFusion significantly outperforms the pivot model in terms of average score. Notably, InfiFusion requires only approximately 1/10000 of the GPU hours compared to LLMs, such as Qwen2.5-14B-Instruct, Phi-4, etc.
In this paper, we introduce InfiFusion, a novel fusion framework that enhances ULD by incorporating Top-K selection and logits standardization. Top-K selection filters out irrelevant logits, reducing noise and computational cost, while Logits Standardization ensures that the pivot model aligns the relative relationships between logits rather than their magnitudes. These innovations improve the efficiency and robustness of knowledge transfer, making it possible to integrate specialized models across different domains. We propose two fusion strategies: Pairwise Fusion (i.e., InfiFusion), where each source model's knowledge is distilled separately into the pivot model, and Unified Fusion (i.e., InfiFusion), which aggregates knowledge from all source models simultaneously. As shown in the figure above, InfiFusion outperforms state-of-the-art models over 11 tasks while significantly reducing computational costs. Unlike traditional models, which demand millions of GPU hours, InfiFusion achieves superior performance with just 160 H800 GPU hours, making it an exceptionally efficient approach.
Our contributions are summarized as follows:
- We introduce InfiFusion, a novel framework that improves knowledge transfer between domain-specialized models by enhancing Universal Logit Distillation (ULD) with Top-K selection and Logits Standardization.
- We propose two fusion strategies: Pairwise Fusion and Unified Fusion, each offering distinct advantages in distilling knowledge from multiple source models into a single pivot model.
- We demonstrate the effectiveness of InfiFusion through extensive experiments, showing that it outperforms state-of-the-art models while significantly reducing computational costs.
Related Work
Model Merging
Model merging integrates models with the same architecture at the parameter level. Wortsman et al. employed a linear averaging method to merge models that were fine-tuned from the same base model. Matena and Raffel introduced Fisher-based model merging, using Laplace approximation and the Fisher information matrix to enhance parameter merging beyond simple averaging. Ilharco et al. used task vectors to represent the differences among source LLMs and applied task arithmetic on these task vectors to achieve model merging. TIES-Merging builds upon this by trimming redundant values and resolving sign conflicts. DARE facilitates the sparsification of task vectors, eliminating over 90% of the delta parameters while maintaining performance. The SCE method is computationally efficient and memory-conserving, merging parameter matrices using a three-step process. Channel merging clusters and merges channel parameters into several groups offline, significantly reducing parameter conflicts.
Knowledge Distillation
Knowledge Distillation enables transferring knowledge from large models to a smaller one while preserving performance. Early approaches focused on aligning the student model's final layer outputs with the teacher's, known as logits distillation. Feature distillation further improves this by utilizing intermediate teacher model features. Distillation can be classified as on-policy or off-policy depending on whether the data is generated during training. While knowledge distillation is widely studied, most research focuses on single-teacher paradigms, with fewer works exploring multi-teacher combinations, which face challenges like vocabulary mismatch, model parameter differences, and task discrepancies.
Model Fusion
Model fusion combines multiple language models to enhance performance and generalization by integrating their predictions or intermediate representations. Unlike traditional merging methods, fusion does not require parallel deployment or models with identical architectures. Fusion techniques typically rely on logits fusion or distribution matrix fusion, achieved through manually designed functions. For instance, MiniLogit proposes logits fusion for multi-teacher collaborative learning in image classification tasks. FuseLLM introduces a method for fusing diverse LLMs by leveraging their generative distributions, while FuseChat proposes a two-stage framework: first, applying pairwise knowledge fusion to create target LLMs with identical structure and size, and then merging these models within the parameter space. In contrast, our approach offers a highly efficient fusion method based on knowledge distillation.
Methods
Preliminary
We consider a pivot language model (LLM) and source LLMs , each specializing in distinct domains or tasks. Our objective is to distill the combined strengths of these source models into a single, integrated pivot model . Given a dataset of instruction--response pairs, we apply knowledge distillation to guide in acquiring complementary expertise from the source models. This process involves defining suitable fusion (distillation) objectives and designing fusion pipelines that integrate diverse knowledge without compromising the overall model quality.
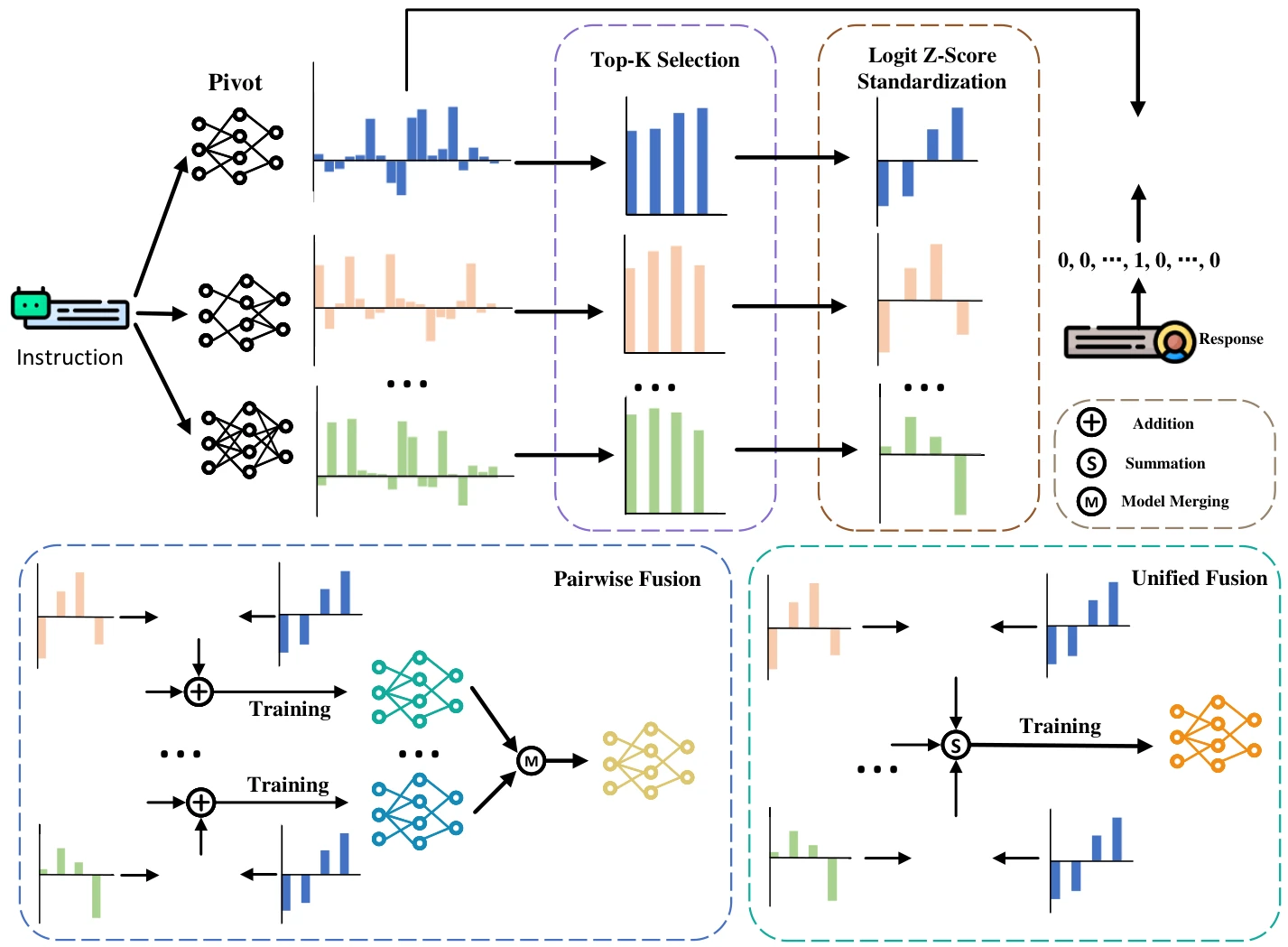
Figure 2: Illustration of the InfiFusion framework, incorporating Top-K selection and logits standardization. Two fusion strategies are proposed: Pairwise Fusion, where each source model's knowledge is distilled separately into the pivot model, and Unified Fusion, which aggregates knowledge from all source models simultaneously.
Supervised Fine-Tuning (SFT). Supervised fine-tuning (SFT) aligns the pivot model with instruction-response pairs in the fine-tuning dataset . For each instruction and its corresponding response of length , the SFT objective is:
where denotes the tokens preceding and is the model-predicted token probability under .
Optimal Transport Loss. OT provides a powerful way to compare two discrete distributions by solving a "mass transport" problem. Formally, let and be two discrete distributions over vocabularies of size and , respectively.. We define:
Here, is the set of joint distributions with marginals and . The cost matrix encodes the cost of "transporting" one unit of mass from token to . In practice, Sinkhorn-based methods with entropic regularization can be used to approximate the above efficiently.
Discrete 1-Wasserstein. An important special case of OT is the 1-Wasserstein distance (also called the Earth Mover's Distance). In discrete settings, is obtained by choosing a particular cost matrix. For instance, if we set (i.e., uniform cost whenever ), the 1-Wasserstein distance has a closed-form solution:
Let be the effective vocabulary size, we augment either the student or teacher vocabulary size through distribution padding (with 0 value), ensuring equal support size for both. where rearranges the probabilities in in descending order. Intuitively, under uniform cost, the optimal transport simply pairs "largest probability mass" with "largest probability mass," the second-largest with the second-largest, and so on. This makes particularly simple and effective for aligning distributions whose labels (tokens) may not match one-to-one.
Universal Logit Distillation Loss. To effectively transfer knowledge from multiple source models to the pivot model , we adopt Universal Logit Distillation (ULD) loss, which aligns probability distributions across different vocabularies using a structured distance metric. Given a source model with vocabulary and the pivot model with vocabulary , their predicted probability distributions at time step are denoted as and , respectively. Since these distributions may not be directly comparable due to vocabulary mismatches, ULD loss mitigates this issue by minimizing the 1-Wasserstein distance:
Here, measures the effort required to transform one probability distribution into another by optimally aligning their probability masses. Unlike KL-divergence, which is sensitive to label mismatches, ULD loss provides a more robust way to distill knowledge across different vocabularies while preserving the semantic structure of the predictions.
Top-K Selection and Logits Standardization
To improve the distillation process, we introduce two strategies: Top-K selection and logits standardization. These techniques aim to enhance knowledge transfer while addressing temperature sharing and vocabulary mismatches between the pivot model and the source models .
Top-K Selection. We focus on the top- logits for both the pivot model and each source model , instead of using the entire logit distribution. This is based on the observation that most logits in instruction-based models correspond to low-probability categories, contributing little to the distillation process. By selecting the top- logits, we reduce noise from irrelevant categories, improving both knowledge transfer quality and computational efficiency. For high-performance instruction models, such as Phi-4, a small value of (e.g., ) captures nearly all the probability mass, enhancing distillation while reducing the computational burden of comparing all logits.
Logits Standardization. To address challenges in temperature sharing, we apply logits standardization to the logits before distillation. Traditional methods assume a shared temperature between the models, which can cause performance issues when the logits' ranges differ. By normalizing the logits, we decouple the magnitude of the logits from the distillation process, allowing the pivot model to focus on their relative order and structure. The logits for both models are normalized as follows:
where , , , and are the mean and standard deviation of the top-K logits for the pivot and source models, respectively. This ensures that the pivot model aligns effectively with the source models, focusing on the relative relationships between logits rather than their magnitudes. Combined with Top-K selection, this preprocessing step ensures more robust and efficient distillation, even when logit distributions differ.
Fusion Strategies
Pairwise Fusion
To integrate knowledge from multiple source models into the pivot model , we adopt a pairwise fusion strategy, where each source model's knowledge is distilled into separately. This fusion is performed by minimizing the Universal Logit Distillation (ULD) loss, incorporating both Top-K selection and logit normalization to enhance the alignment process.
For each source model , we first apply Top-K selection to the original logits , retaining the most informative logits , i.e., . We then normalize the logits using logits standardization. The resulting loss is computed as:
where and are the normalized logits for the student and teacher models, respectively, at time step . By minimizing this loss, we encourage the student model to align its predictions with the teacher's on the most probable tokens, while reducing the impact of irrelevant logits. Let be the optimized pivot model, its parameters are are obtained via:
is the hyper-parameter balancing the losses. By looping from to , which indicates we perform times of training, we obtain . Given share the same architecture, they can be merged via model merging methods and obtain the final model .
Unified Fusion
To aggregate knowledge from multiple teacher models, we adopt a unified fusion strategy. In this approach, the knowledge from each source model is distilled into the pivot model by computing the pairwise fusion loss for each teacher, summing the losses, and combining them with the supervised fine-tuning (SFT) loss to form the final objective function. For each source model , the pairwise fusion loss is computed using Top-K selection and logits standardization. The total loss is then given by:
where controls the balance between the distillation and supervised fine-tuning losses. The parameters of the pivot model are optimized as:
The result of this fusion process is the unified pivot model , which benefits from both the labeled data in the fine-tuning dataset and the distilled knowledge from the source models, focusing on the most relevant logits via Top-K selection and logits standardization.
Pairwise fusion and unified fusion are proposed as two independent approaches for achieving multi-source model fusion. They are based on different assumptions. Specifically, unified fusion defines an explicit global loss and assumes that the optimal weights for this loss will yield the best performance. In contrast, pairwise fusion defines an objective loss implicitly. It aims to achieve local optimization and assumes that the average of these local optima will result in the best overall performance. We provide a detailed theoretical analysis about the relation between pairwise fusion and unified fusion in the Appendix.
Experiments
Settings
Dataset. In our fusion experiments, we create an InfiFusion-Mix dataset, which consists of 180,000 samples used for facilitating knowledge transfer from the source model to the pivot model. The samples in this dataset are sourced from Infinity-Instruct, ScaleQuest-Math, and opc-sft-stage2. The InfiFusion-Mix dataset is split into train and test sets at an 8:2 ratio, resulting in 144k training and 36k test samples.
| Types | General Data | Math Data | Code Data |
|---|---|---|---|
| Dataset | Infinity-Instruct | ScaleQuest-Math | opc-sft-stage2 |
| Original Size | 1.4M | 1.0M | 436K |
| Sample Size | 80K | 50K | 50K |
Training Details. We train all models using the C-AdamW optimizer with a cosine annealing scheduler for a total of 5 epochs. Early stopping is applied at the 4th epoch to prevent overfitting and reduce GPU costs. The entire training of InfiFusion takes approximately 20 hours, utilizing a global batch size of 16 across GB NVIDIA H800 GPUs, with a learning rate of . By default, we set .
Offline Teacher Loading. Since the source models are static, we can pre-extract their hidden states (before the lm_head layer). For each source model, the hidden states are first compressed and stored on disk, requiring approximately 1.5 TB for InfiFusion-Mix. Each source model only retains a single fully connected layer (i.e., lm_head), which significantly speeds up the InfiFusion training process, making it comparable to the training of pure SFT models. Moreover, this approach greatly reduces the GPU memory footprint of fusion.
Evaluation. We evaluate our models across multiple domains, using 11 different benchmarks that cover a wide range of fields, including general reasoning, mathematics, coding, and text reasoning. Specifically, we assess the model's mathematical capabilities with benchmarks such as GSM8K, Math, and TheoremQA. For coding, we use MBPP+ and HumanEval, while general reasoning is evaluated through BBH, ARC-C and MMLU. We also test instruction-following ability with IFEval, and text reasoning performance using DROP and Hellaswag.
Pivot Model and Source Models. Before choosing the pivot model, we evaluate the performance of state-of-the-art open-source LLMs across 11 benchmarks. To maintain both high training efficiency and strong performance, we select the powerful instruction-following model Phi-4 as the pivot model, and use Qwen2.5-Coder-14B-Instruct, Qwen2.5-14B-Instruct, and Mistral-Small-24B-Instruct-2501 as the source models. By fusion, the strengths of the source models are aggregated and integrated into the pivot model.
Main Results
| Models | GSM8K | MATH | ThQA | MBPP+ | HEval | BBH | ARC-C | MMLU | IFEval | DROP | HS | Avg | Params | GPU Hours |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pivot Model | ||||||||||||||
| Phi-4 | 86.88 | 74.10 | 36.12 | 64.29 | 82.93 | 65.90 | 86.78 | 81.38 | 76.50 | 88.49 | 85.57 | 75.08 | 14B | ~1.0M |
| Source Models | ||||||||||||||
| Qwen2.5-14B-Coder | 88.25 | 70.24 | 30.88 | 72.75 | 89.63 | 71.07 | 87.12 | 73.84 | 76.62 | 84.49 | 81.08 | 75.09 | 14B | ~1.8M |
| Qwen2.5-14B-Instruct | 90.14 | 74.32 | 19.50 | 69.04 | 79.88 | 72.70 | 88.81 | 79.38 | 86.33 | 85.50 | 86.55 | 75.65 | 14B | ~1.8M |
| Mistral-small-24B | 92.72 | 69.48 | 40.38 | 67.22 | 79.27 | 81.67 | 85.08 | 78.92 | 83.21 | 86.68 | 86.71 | 77.39 | 24B | ~1.6M |
| SFT | ||||||||||||||
| SFT (Phi-4) | 90.75 | 71.96 | 37.88 | 71.00 | 78.05 | 83.03 | 92.88 | 80.28 | 77.22 | 87.69 | 86.79 | 77.96 | 14B | 145 |
| Model Fusion via Distillation | ||||||||||||||
| SeqKD* | 89.23 | 73.06 | 28.62 | 69.80 | 81.10 | 81.03 | 92.88 | 79.97 | 82.13 | 87.40 | 75.34 | 76.41 | 14B | 580 |
| MiniLogit* | 90.33 | 73.34 | 41.49 | 69.22 | 82.41 | 81.36 | 91.19 | 80.15 | 78.41 | 87.56 | 86.99 | 78.40 | 14B | 220 |
| FuseLLM* | 89.95 | 72.76 | 41.28 | 69.44 | 81.34 | 82.17 | 91.63 | 79.74 | 78.94 | 86.97 | 86.86 | 78.28 | 14B | 225 |
| FuseChat* | 89.86 | 74.21 | 44.06 | 70.18 | 82.19 | 81.77 | 91.08 | 79.66 | 78.09 | 87.94 | 86.67 | 78.70 | 14B | 650 |
| Pairwise Fusion | ||||||||||||||
| InfiFusion & TA | 90.98 | 74.70 | 46.50 | 72.20 | 82.93 | 83.62 | 92.20 | 80.34 | 79.86 | 88.73 | 87.52 | 79.96 | 14B | 450 |
| InfiFusion & TIES | 90.22 | 74.32 | 42.12 | 72.75 | 85.98 | 83.19 | 91.19 | 80.48 | 79.14 | 88.53 | 87.73 | 79.60 | 14B | 450 |
| InfiFusion & SCE | 90.22 | 74.40 | 42.00 | 70.60 | 85.37 | 83.24 | 91.19 | 80.37 | 80.34 | 88.60 | 87.72 | 79.46 | 14B | 450 |
| Unified Fusion | ||||||||||||||
| InfiFusion | 90.45 | 74.92 | 45.75 | 73.02 | 82.93 | 83.44 | 92.88 | 80.18 | 79.50 | 88.71 | 87.38 | 79.92 | 14B | 160 |
* denotes methods re-implemented and trained on our dataset, pivot, and source models.
InfiFusion achieves nearly identical performance (79.92 vs. 79.96) compared to InfiFusion & TA, while utilizing only approximately 35% of the GPU hours (theoretically approximated as , and here ). InfiFusion achieves 79.92 (vs. 75.08 for Phi-4), while requiring only about 0.016% of the GPU hours. TA, TIES, and SCE represent different merging methods.
Pairwise and Unified Fusion
Pairwise Fusion. In pairwise fusion, the pivot and source models are grouped into several model pairs. Each pair is then trained using the pairwise fusion loss, resulting in fused models. These fused models share the same architecture as the pivot model but have distinct weights. They are subsequently merged using commonly used methods, such as Task Arithmetic, Ties-Merging, and SCE. As shown in the table above, the pairwise fused model outperforms the pivot model, Phi-4, across 10 benchmarks. Specifically, the InfiFusion & TA model achieves an average score improvement of 4.88 points. Additionally, InfiFusion significantly surpasses the source models, with average score improvements of 4.87, 4.31, and 2.57 for Qwen2.5-14B-Coder, Qwen2.5-14B-Instruct, and Mistral-small-24B, respectively. We observe that TIES and SCE exhibit moderate performance drops compared to TA. We attribute this to the presence of a hyperparameter, , in both methods, which demands precise tuning. In this study, we use the default value to emphasize the robustness of the InfiFusion approach. While more precise tuning of this hyperparameter could potentially enhance performance, such an investigation lies beyond the scope of this paper.
Unified Fusion. In unified fusion, all source models are fused with the pivot model simultaneously. However, this approach presents two key challenges: token misalignment and conflicts arising from the diversity of source models. To address these, we introduce a ULD loss and a Top-K selection mechanism. The ULD loss provides an effective way to measure the distance between distributions of different sizes, mitigating issues caused by token misalignment. Meanwhile, the Top-K selection reduces noise from small logits and alleviates conflicts stemming from the varying styles of the source models.
As shown in the table above, unified fusion, which leverages the strengths of the source models, significantly outperforms the pivot model by 4.84 points. Similarly, when compared to the source models, InfiFusion surpasses them, with average score improvements of 4.83, 4.27, and 2.53 for Qwen2.5-14B-Coder, Qwen2.5-14B-Instruct, and Mistral-small-24B, respectively. InfiFusion delivers performance nearly identical to InfiFusion & TA, with only a 0.04-point difference on average, while consuming only 35% of the GPU hours required by InfiFusion & TA.
Comparison with State-of-the-art Methods
We evaluate five methods: SFT, SeqKD, MiniLogit, FuseLLM, and FuseChat. SFT involves directly fine-tuning the Phi-4 model on our InfiFusion-Mix dataset with only the SFT loss. The performance improves from 75.08 to 77.96, demonstrating the effectiveness of InfiFusion-Mix. With the incorporation of the fusion loss, performance improves further to 79.92 for InfiFusion and 79.96 for InfiFusion, highlighting the efficacy of our fusion approach. SeqKD generates data using all the source models, where each model generates the same volume of InfiFusion-Mix data, thereby expanding the training dataset. However, despite the addition of (here ) times more generated data, SeqKD results in worse performance than SFT. This suggests that simply adding more generated data may lead to confusion for the pivot model. MiniLogit and FuseLLM both utilize unified fusion. MiniLogit, a commonly used logit fusion method for image classification tasks, and FuseLLM, which applies a simple MinCE distribution fusion for LLMs, both yield lower performance than InfiFusion. This is attributed to the superiority of ULD with Top-K selection and logits standardization compared to the KL divergence loss used by these methods. FuseChat adopts pairwise fusion, achieving a moderate higher average score than FuseLLM, but at the cost of requiring nearly (here ) times more GPU resources for training.
Ablation Study
Logits Standardization and Top-K Selection. To evaluate the impact of logits standardization and Top-K selection, we compare models trained with and without these techniques. As shown in the following table, applying only Top-K selection results in a notable performance improvement, from 79.02 to 79.66. In contrast, logits standardization alone yields a smaller gain. When both techniques are combined, InfiFusion achieves further performance improvements, reaching 79.92. These results suggest that focusing on the most informative logits can be effective.
| Method | Top-K Selection | Logits Standardization | Avg |
|---|---|---|---|
| InfiFusion | 79.02 | ||
| InfiFusion | ✓ | 79.66 | |
| InfiFusion | ✓ | 79.29 | |
| InfiFusion | ✓ | ✓ | 79.92 |
Number of Source Models. Next, we explore the effect of increasing the number of source models in the fusion process. Specifically, we investigate two configurations: (1) fusing the pivot model with a single source model, and (2) fusing the pivot model with multiple source models simultaneously using the pairwise/unified fusion strategy. The following table presents the results of this ablation study.
| Models | Qwen-Coder | Qwen-Instruct | Mistral | Avg. | GPU Hours |
|---|---|---|---|---|---|
| Pivot model: Phi-4 | |||||
| Phi-4 SFT | - | - | - | 77.96 | 145 |
| InfiFusion | |||||
| ✓ | ✓ | 79.56 | 300 | ||
| ✓ | ✓ | 79.40 | 300 | ||
| ✓ | ✓ | 79.39 | 300 | ||
| ✓ | ✓ | ✓ | 79.96 | 450 | |
| InfiFusion | |||||
| ✓ | 78.70 | 150 | |||
| ✓ | 78.65 | 150 | |||
| ✓ | 79.61 | 150 | |||
| ✓ | ✓ | 79.54 | 155 | ||
| ✓ | ✓ | 79.45 | 155 | ||
| ✓ | ✓ | 79.31 | 155 | ||
| ✓ | ✓ | ✓ | 79.92 | 160 |
It is evident that when fusing a single source model, the average score improves from 77.96 to 78.70, 78.65, and 79.61, for Qwen2.5-Coder-14B, Qwen2.5-14B-Instruct and Mistral-small-24B, respectively. As more source models are fused, both pairwise and unified fusion strategies yield substantial performance improvements. Notably, InfiFusion exhibits performance close to that of InfiFusion, while requiring approximately of the training GPU hours.
Value of . We also investigate the effect of varying the value of in Top-K selection. From the following table, we observe that when is too small (i.e., ), the knowledge transfer quality decreases due to too few logits being considered during fusion. Conversely, when is too large (i.e., ), noise is introduced, which degrades performance. Consequently, we select as it yields the best performance. Interestingly, this aligns with our observation that for high-performance instruction models like Phi-4, a small value of (e.g., ) captures nearly all of the probability mass.
| 5 | 10 | 15 | 20 | 25 | |
|---|---|---|---|---|---|
| Avg. | 79.54 | 79.92 | 79.46 | 79.41 | 79.39 |
Dataset Scaling. We conduct an ablation study to assess the impact of data scaling on InfiFusion by varying the size of the training dataset. Specifically, we train models with datasets ranging from 50k to 144k instruction-response pairs. As shown in the following table, increasing the training data size consistently improves InfiFusion's performance. This emphasizes the value of dataset scaling and indicates that our method benefits from larger datasets, leading to enhanced performance.
| Dataset Scale | 50,000 | 100,000 | 144,000 |
|---|---|---|---|
| Avg. | 79.24 | 79.49 | 79.92 |
Conclusion
We present InfiFusion, an innovative framework that seamlessly integrates domain-specialized LLMs into a unified pivot model, enhancing Universal Logit Distillation (ULD) through Top-K selection and logits standardization. InfiFusion effectively distills knowledge from diverse source models, overcoming vocabulary mismatches and computational inefficiencies. Two fusion strategies, Pairwise Fusion (InfiFusion) and Unified Fusion (InfiFusion), offer flexibility in merging expertise. Experiments reveal that InfiFusion surpasses state-of-the-art models, such as Qwen-2.5-14B-Instruct and Phi-4, across 11 benchmark tasks, achieving superior performance with only 160 H800 GPU hours. InfiFusion stands as an efficient and scalable solution for high-performance LLM deployment.
Limitations
While our unified fusion approach offers a straightforward and promising framework, it does not consistently outperform the pairwise fusion strategy. Additionally, the current method is limited to large language models (LLMs), and the fusion of models similar to GPT-O1 has not yet been explored. Another limitation is that the source models should not lag too far behind the pivot model in terms of performance, which restricts the selection of viable source models. In future work, we aim to relax this constraint, allowing for more flexible model selection. We also plan to extend our fusion approach to include both traditional instruct LLMs and GPT-O1-like models, thereby broadening the scope of model capabilities.
Appendix
The Relationship between Unified and Pairwise Fusion
In this session, we analyze the relationship between unified fusion and pairwise fusion. First, we will generalize the loss function for unified fusion.
where , and is defined above, respectively. Therefore, to find the optimal for the Unified is to solve the optimization problem:
In the scenario of the pairwise fusion, we can obtain fused models, where we have
where is a scaling factor and . Let
Note that when , , we have
The optimization problem can be rewritten as
and for , can be written as:
The final fused model is derived via weight averaging
In unified fusion, the loss can be explicitly written in a function of
whereas for the pairwise fusion, is not explicitly defined. However, we can assume that the exists such that when
we have
Ideally, unified fusion can infinitely approximate the global optimum of its defined objective function, but it highly depends on the effectiveness of the loss function. Therefore, a well-designed loss, which is favorable for network optimization, mitigates the conflicts between source models and reflects the real world evaluation becomes essential. By comparison, pairwise fusion looks like an experimental tool, as no theory can support the assumption that the average of local optima can lead to the high performance. The future work should be centered around improving the merging methods, instead of simply averaging but more complexity combinations of the local optima.
Model Selection
The guiding philosophy of InfiFusion is to elevate the capabilities of smaller LLMs through the strategic fusion and integration of models, thereby enabling the efficient attainment of high-performance, compact LLMs. Accordingly, we focus our evaluation on state-of-the-art models with fewer than 30B parameters. For the purpose of efficient training on a single node equipped with GB H800 GPUs, we impose an additional constraint, limiting the pivot model to fewer than 20B parameters. To achieve optimal performance, we select Phi-4 as the pivot model and include Qwen2.5-14B-Instruct, Qwen2.5-Coder-14B-Instruct, and Mistral-Small-24B-Instruct-2501. These models have demonstrated performance either on par with or exceeding that of the pivot model.
| Models | GSM8K | MATH | ThQA | MBPP+ | HEval | BBH | ARC-C | MMLU | IFEval | DROP | HS | Params | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Opencoder-8B-Instruct | 31.54 | 10.92 | 14.50 | 63.80 | 81.10 | 46.08 | 49.83 | 42.24 | 54.08 | 39.69 | 43.20 | 8B | 43.36 |
| Llama3.1-8B-Instruct | 79.78 | 49.04 | 32.38 | 59.40 | 68.29 | 67.78 | 81.69 | 69.50 | 85.13 | 82.34 | 73.84 | 8B | 68.11 |
| phi-4 | 86.88 | 74.10 | 36.12 | 64.29 | 82.93 | 65.90 | 86.78 | 81.38 | 76.50 | 88.49 | 85.57 | 14B | 75.08 |
| DeepSeek-Coder-V2-Lite-Instruct | 85.06 | 60.20 | 19.88 | 72.40 | 75.00 | 62.22 | 71.53 | 62.62 | 62.83 | 74.63 | 68.01 | 14B | 64.94 |
| Qwen2.5-14B-Instruct | 90.14 | 74.32 | 19.50 | 69.04 | 79.88 | 72.70 | 88.81 | 79.38 | 86.33 | 85.50 | 86.55 | 14B | 75.65 |
| Qwen2.5-Coder-14B-Instruct | 88.25 | 70.24 | 30.88 | 72.75 | 89.63 | 71.07 | 87.12 | 73.84 | 76.62 | 84.49 | 81.08 | 14B | 75.09 |
| Falcon3-10B-Instruct | 54.66 | 46.46 | 45.88 | 66.20 | 71.95 | 75.78 | 51.53 | 74.63 | 83.33 | 78.06 | 81.57 | 10B | 66.36 |
| Llama-3.1-Tulu-3-8B | 82.26 | 45.56 | 29.25 | 47.00 | 63.41 | 68.73 | 65.76 | 65.81 | 87.41 | 76.64 | 71.74 | 8B | 63.96 |
| Qwen-2.5-Coder-7B-Instruct | 81.73 | 62.10 | 22.62 | 72.20 | 87.80 | 60.45 | 84.41 | 66.16 | 69.30 | 77.92 | 76.20 | 7B | 69.17 |
| starcoder2-15b-instruct-v0.1 | 24.41 | 13.96 | 18.00 | 62.40 | 65.85 | 18.99 | 44.75 | 49.60 | 46.40 | 50.91 | 24.05 | 15B | 38.12 |
| OpenMath2-Llama3.1-8B | 85.37 | 65.68 | 25.25 | 14.00 | 9.15 | 45.33 | 45.08 | 32.29 | 32.01 | 74.42 | 32.06 | 8B | 41.88 |
| internlm3-8b-instruct | 85.14 | 72.46 | 18.62 | 57.80 | 80.49 | 55.62 | 77.97 | 73.26 | 86.81 | 83.39 | 89.76 | 8B | 71.03 |
| Mistral-Small-24B-Instruct-2501 | 92.72 | 69.48 | 40.38 | 67.22 | 79.27 | 81.67 | 85.08 | 78.92 | 83.21 | 86.68 | 86.71 | 24B | 77.39 |
Case Study
The following table shows three examples where Phi-4 is wrong but InfiFusion is correct. These three problems come from GSM8K, HumanEval, and Hellaswag, corresponding to math, coding, and text reasoning domains. Phi-4 misunderstood the phrase 'two times older than' in the question from GSM8K. For the problem from HumanEval, Phi-4 got the index of the number for the quantity of oranges wrong. Phi-4 also failed to make the correct reasoning in the question from Hellaswag, where Option A, 'cuts something on a knife board using an electric tool,' represents an impossible action. These errors were corrected in InfiFusion, indicating that InfiFusion indeed performs better on more tasks and possesses stronger reasoning capabilities.
Case 1: GSM8K (Math)
Prompt: Brandon's iPhone is four times as old as Ben's iPhone. Ben's iPhone is two times older than Suzy's iPhone. If Suzy's iPhone is 1 year old, how old is Brandon's iPhone? Please reason step by step, and put your final answer within \boxed.
Phi-4: Determines Ben's iPhone is years old, then Brandon's iPhone is years old. Final answer: .
InfiFusion: Determines Ben's iPhone is years old, then Brandon's iPhone is years old. Final answer: .
Case 2: HumanEval (Coding)
Prompt: Implement fruit_distribution(s, n) that takes a string like "5 apples and 6 oranges" and a total number of fruits, and returns the number of mango fruits.
Phi-4: Uses oranges = int(words[4]) which gets the wrong index for the number of oranges.
def fruit_distribution(s, n):
words = s.split()
apples = int(words[0])
oranges = int(words[4])
mangoes = n - apples - oranges
return mangoes
InfiFusion: Iterates through the words to find the numbers before "apples" and "oranges", correctly handling the input format.
def fruit_distribution(s, n):
fruits = s.split()
apples = 0
oranges = 0
for i in range(len(fruits)):
if fruits[i] == "apples":
apples = int(fruits[i-1])
elif fruits[i] == "oranges":
oranges = int(fruits[i-1])
mangoes = n - apples - oranges
return mangoes
Case 3: Hellaswag (Text Reasoning)
Prompt: A woman is reading a newspaper nearby while he speaks to her and shows her something in his hand. The man sharpens his knives using an electric tool. He — Question: Which ending makes the most sense? A. sharpens and cuts something on a knife board using an electric tool. B. then continues cutting his onion. C. travels with his knife under the table and uses it also in his shoe. D. then shows her a spare knife that he has also used on a knife sharpener and drills into a side of the table.
Phi-4: Chose A — "sharpens and cuts something on a knife board using an electric tool." This is an impossible action.
InfiFusion: Chose B — "then continues cutting his onion." This is the correct and logical continuation.
BibTeX
@article{yan2025infifusion,
title={InfiFusion: A Unified Framework for Enhanced Cross-Model Reasoning via LLM Fusion},
author={Zhaoyi Yan, Yiming Zhang, Baoyi He, Yuhao Fu, Qi Zhou, Zhijie Sang, Chunlin Ji, Shengyu Zhang, Fei Wu, Hongxia Yang},
journal={arXiv preprint arXiv:2501.02795},
year={2025}
}