InfiMed-ORBIT: Aligning LLMs on Open-Ended Complex Tasks via Rubric-Based Incremental Training
ABSTRACT
ORBIT is an open-ended rubric-based incremental training framework for high-stakes medical dialogue. It combines synthetic dialogue generation, retrieval-augmented rubric construction, difficulty filtering, and rubric-guided reinforcement learning to align LLMs on context-dependent consultation tasks. Applied to Qwen3-4B-Instruct, ORBIT raises the HealthBench-Hard score from 7.0 to 27.5 using only 2k training samples, with larger rubric sets improving performance to 33.6 and 37.3.
ORBIT is a rubric-guided reinforcement learning framework for aligning LLMs on open-ended medical dialogue.
Abstract
Reinforcement learning has powered many recent breakthroughs in large language models, especially for tasks where rewards can be computed automatically, such as code generation. However, RL is less reliable in open-ended medical dialogue, where feedback is ambiguous, context-dependent, and difficult to collapse into a single scalar signal. This often requires heavily supervised reward models and risks reward hacking.
ORBIT is an open-ended rubric-based incremental training framework for high-stakes medical dialogue. It integrates synthetic dialogue generation with dynamically constructed rubrics that serve as adaptive guides for incremental RL. Unlike approaches that rely on external medical knowledge bases or handcrafted rules, ORBIT uses rubric-guided evaluation and can be implemented with general-purpose instruction-following LLMs, avoiding task-specific judge fine-tuning.
Applied to Qwen3-4B-Instruct, ORBIT raises the HealthBench-Hard score from 7.0 to 27.5 using only 2k training samples. With larger rubric sets, ORBIT remains competitive with the strongest open-source baselines and consistently improves consultation quality across diverse medical scenarios. The same rubric pipeline also improves InfoBench instruction-following performance.
Introduction
As high-quality pretraining data become harder to expand and model scaling brings smaller marginal gains, progress increasingly comes from post-training. Supervised fine-tuning aligns models to target behaviors with token-level demonstrations, while reinforcement learning optimizes policies against preference objectives. In domains with explicit, verifiable ground truth, RL with verifiable rewards can deliver reliable gains.
Medical consultation is different. Response quality depends on multiple context-sensitive axes, including safety, empathy, clinical appropriateness, context awareness, and completeness. Reducing such judgments to a single opaque scalar reward is fragile, expensive, and hard to transfer. In high-stakes dialogue, this can also amplify reward hacking risks.
Rubric-based evaluation provides a more interpretable alternative. Rubrics decompose response quality into explicit criteria and support transparent credit assignment. HealthBench shows the value of expert-designed rubrics for clinical reasoning, but existing medical LLMs still perform poorly on HealthBench-Hard, exposing a gap between QA-style optimization and realistic consultation.
ORBIT addresses this gap by using a small collection of rubric examples to guide evaluation. Through retrieval-augmented in-context prompting, it directs a general-purpose judge model to assess responses against query-specific criteria inside an incremental RL framework.
The contributions are:
- Rubric-based open-ended alignment: ORBIT replaces opaque scalar rewards and costly reward models with interpretable, rubric-driven feedback for high-stakes medical dialogue.
- Context-aware rubric generation and training: the pipeline combines retrieval-augmented in-context prompting, multi-stage filtering, dynamic sampling, and incremental optimization.
- Empirical validation: ORBIT substantially improves HealthBench-Hard and transfers to InfoBench, suggesting that rubric-guided RL is useful beyond medical dialogue.
Related Work
Open-Ended Benchmarks
LLM evaluation for open-ended generation is shifting from short-form automatic metrics toward holistic rubric-based frameworks. Benchmarks such as HealthBench, PaperBench, WildBench, AMEGA, and MultiChallenge define fine-grained criteria across diverse scenarios. HealthBench is especially relevant because it tests realistic medical consultation, where response quality is multidimensional and context-dependent.
Reward Models in LLMs
RLHF and related post-training methods usually depend on reward models or rule-based reward signals. Rule-based rewards work when criteria are explicit and verifiable, while learned reward models can approximate human judgment but are expensive to construct, domain-dependent, and sensitive to distribution shift. ORBIT instead uses automatically derived, case-specific rubrics to provide structured and transparent feedback.
LLMs for Health
Medical LLM research spans differential diagnosis, clinical documentation, mental health assistance, radiology reporting, and agentic clinical reasoning. Many systems remain specialized to narrow tasks and struggle with heterogeneous, context-dependent reasoning. ORBIT targets this open-ended setting by aligning models with clinical consultation rubrics rather than only training on question-answer style supervision.
ORBIT Framework
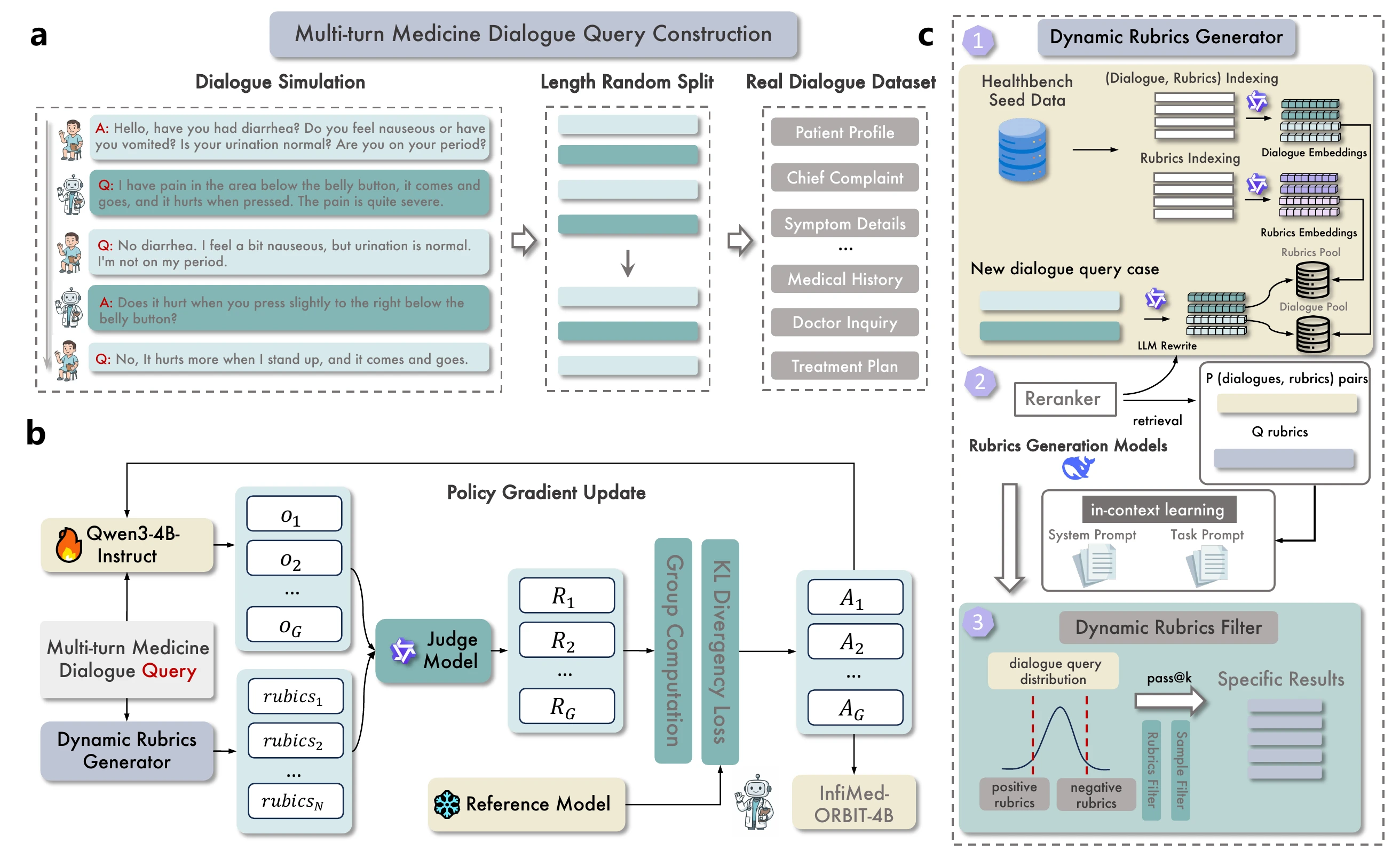
Given a clinical case in chat format or outpatient chart format, ORBIT turns it into practical RL training data. The system produces final <dialogue, rubrics> pairs through three stages: dialogue QA simulation, rubric generation with in-context learning, and rubric-based reinforcement learning.
Dialogue QA Simulation
ORBIT uses patient query dialogues from DoctorAgent-RL as seeds for simulated consultations and supplements them with additional open-source medical dialogue datasets. These sources provide realistic multi-turn consultation contexts. After dialogue QA data are prepared, advanced LLMs generate rubrics step by step through in-context learning.
Rubric Generation With In-Context Learning
ORBIT builds a diagnostic database from seed HealthBench rubrics. Each consultation dialogue and rubric is embedded and stored in vector pools:
- a case-rubric pair pool that keeps each case together with its rubric set;
- a rubric pool that collects unique rubric criteria and their embeddings.
For a new consultation query, ORBIT retrieves similar cases and semantically aligned rubric candidates, reranks them, and prompts a generation model to synthesize a query-specific checklist. The generated rubric set is used only by the judge model for response evaluation.
Difficulty Filtering With Pass@k
ORBIT filters both queries and rubrics to focus RL on useful learning signals. For each query, the current model generates multiple rollouts and the judge scores response-rubric pairs.
The average query score is:
High-scoring cases are too easy, while very low-scoring cases may be unsolved. ORBIT keeps cases in an intermediate difficulty band.
At the rubric level, the pass rate is:
Rubrics with very high pass rates are removed because they provide little learning signal.
Rubric-Based Reinforcement Learning
ORBIT optimizes the policy with Group Relative Policy Optimization (GRPO). For each query, it samples a group of outputs and computes advantages from the group mean and standard deviation of rubric rewards.
The rubric-aware reward is:
This gives dense, semantic feedback over clinical reasoning steps rather than only final answers.
ORBIT adds two stability strategies:
- Variance-aware dynamic sampling: batches with near-zero reward variance are filtered so updates come from discriminative samples.
- Staged entropic restarts: at stage transitions, the policy starts from the best previous checkpoint while sampling temperature is reset to reintroduce exploration.
Experiments
Settings
The primary experiments use Qwen3-4B-Instruct-2507 as the base model and Qwen3-30B-Instruct-2507 as the rubric evaluation judge during training. The main benchmark is HealthBench-Hard, a challenging 1k-case subset of HealthBench designed to test open-ended medical consultation.
The data are organized into:
- Core Experimental Dataset: 2,082 multi-turn consultations from IMCS21, CHIP-MDCFNPC, and MedDG.
- Scalability Dataset: roughly 8k curated samples from DoctorAgent-RL.
- Large-Scale Validation Dataset: 20k additional samples from ReMeDi.
To avoid contamination, HealthBench-Hard samples are excluded from seed data. Only non-Hard HealthBench-4k rubrics are used for RAG seed examples, with additional lexical and semantic filtering.
HealthBench-Hard Results
ORBIT substantially improves smaller open-source models and allows a 4B model to compete with much larger systems.
| Model | Emergency referrals | Context seeking | Global health | Health data tasks | Communication | Hedging | Response depth | Accuracy | Completeness | Communication quality | Context awareness | Instruction following | Total Score |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4.1 | 20.5 | 12.3 | 12.1 | 9.7 | 14.9 | 12.3 | 17.5 | 30.5 | 0 | 70.6 | 0 | 60.5 | 13.2 |
| GPT-5 thinking | - | - | - | - | - | - | - | - | - | - | - | - | 46.2 |
| Qwen3-4B-Instruct base | 9.3 | 8.5 | 7.1 | 0 | 8.6 | 12.2 | 5.1 | 24.1 | 0.8 | 57.5 | 0 | 45.0 | 7.0 |
| Qwen3-4B-Thinking | 14.4 | 12.5 | 2.4 | 0 | 3.5 | 8.5 | 0 | 23.2 | 0 | 42.5 | 0 | 39.6 | 5.2 |
| InfiMed-ORBIT-4B (2k) | 39.9 | 37.8 | 30.2 | 6.2 | 26.6 | 32.2 | 6.6 | 31.8 | 38.1 | 45.3 | 16.8 | 43.7 | 27.5 |
| InfiMed-ORBIT-4B (8k) | 44.6 | 49.1 | 34.6 | 9.3 | 28.0 | 42.6 | 10.4 | 33.6 | 42.0 | 46.7 | 32.3 | 50.5 | 33.6 |
| InfiMed-ORBIT-4B (28k) | 51.6 | 50.5 | 41.9 | 10.8 | 30.9 | 43.8 | 13.4 | 38.1 | 48.9 | 42.1 | 31.3 | 49.1 | 37.3 |
| Qwen3-30B-Instruct | 18.3 | 12.9 | 14.7 | 17.9 | 19.4 | 9.5 | 28.5 | 28.5 | 0 | 45.2 | 0 | 33.7 | 13.1 |
| Baichuan-M2-32B | 45.6 | 39.5 | 35.6 | 21.3 | 32.0 | 40.9 | 19.9 | 41.3 | 44.6 | 51.6 | 19.3 | 48.0 | 34.5 |
With 2k samples, ORBIT improves the total score from 7.0 to 27.5, a 293% relative improvement. Scaling to 8k and 28k samples further raises the score to 33.6 and 37.3.
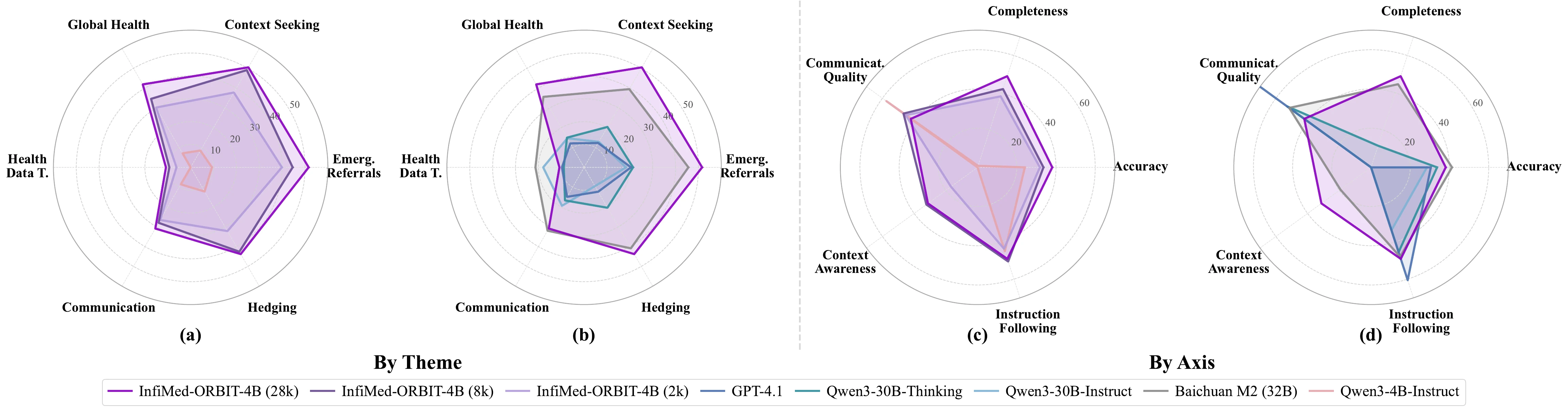
Multi-dimensional performance comparison by clinical theme and evaluation axis.
Ablations and Data Efficiency
ORBIT studies the effects of rubric model selection, judge selection, pass@k filtering, dynamic sampling, and multi-stage restart training. The core finding is that not all samples and rubrics contribute equally: easy samples and redundant rubrics can add computation without useful gradients.
| Setting | Total Score |
|---|---|
| Qwen3-4B-Instruct base | 7.2 |
| InfiMed-ORBIT-4B, no filter | 20.2 |
| Rubric pass@k filter 0-0.75 | 19.9 |
| Rubric pass@k filter 0-0.50 | 17.9 |
| Rubric pass@k filter 0-0.25 | 18.7 |
| Sample pass@k filter 0-0.75 | 19.7 |
| Sample pass@k filter 0-0.50 | 14.5 |
| InfiMed-ORBIT-4B, 8k data | 25.9 |
| InfiMed-ORBIT-4B, restart | 27.3 |
Selective filtering improves the compute-performance tradeoff. Multi-stage restart training further improves the 8k setting from 25.9 to 27.3 under the GPT-OSS-120B-middle evaluation setup.
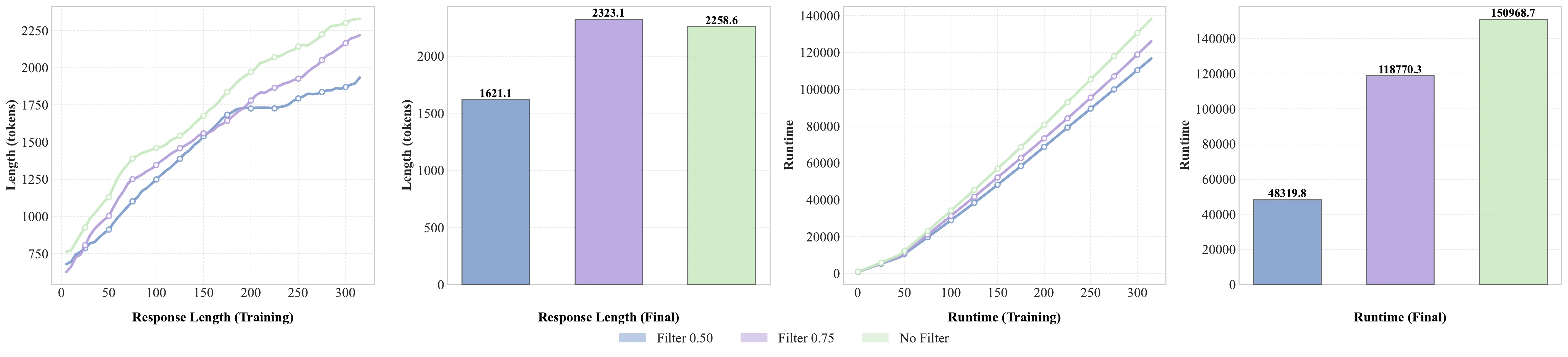
Filtering controls output length and training runtime while preserving useful reward signals.
Rubric-RL Versus Inference Scaling
The paper compares inference scaling on the baseline Qwen3-4B-Instruct model with ORBIT-trained models. Increasing baseline rollouts from K=8 to K=40 only gives marginal improvements, suggesting a capability ceiling. ORBIT instead reshapes the model distribution: high-scoring, rubric-compliant responses become much more likely, rather than appearing only through sampling luck.
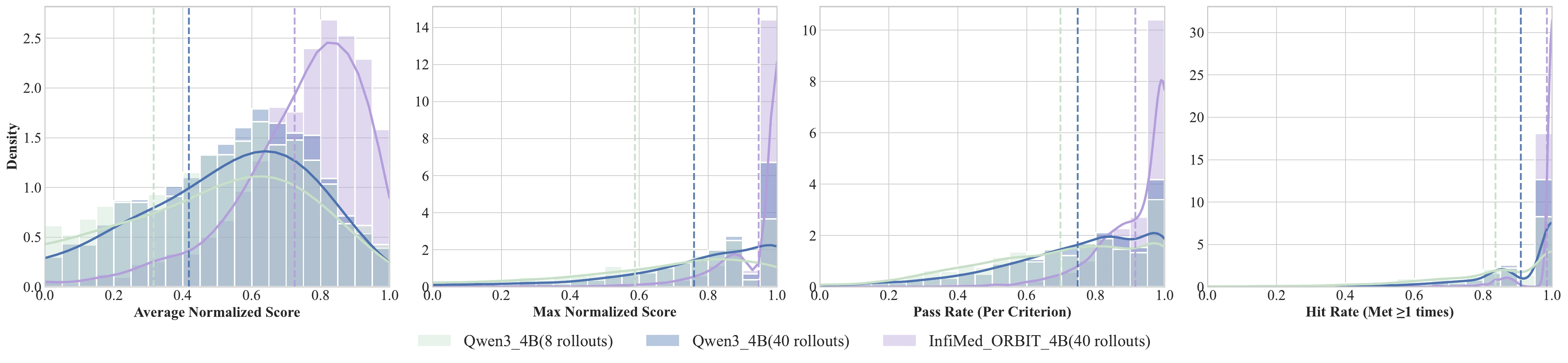
Rubric-guided RL shifts the policy distribution toward high rubric compliance beyond inference scaling alone.
Generalization to InfoBench
ORBIT is also evaluated on InfoBench, an open-ended instruction-following benchmark. Using the easy split as seed data and retrieving 2k WildChat samples for rubric-augmented RAG, ORBIT improves Qwen3-4B-Base from 42.0 to 82.9 on the hard split. This suggests that rubric-based reinforcement learning can generalize beyond medical dialogue.
Supplementary Analysis
Rubric Generator
The supplementary material describes a retrieval-augmented rubric generator. It retrieves reference cases relevant to a medical scenario and uses them as in-context examples for rubric generation. The prompt explicitly asks for both positive criteria and negative criteria, so the judge can reward desirable behaviors and penalize unsafe or incomplete behaviors.
Judge and Rubric Model Selection
The paper compares several open-source judge models against GPT-4.1. GPT-OSS-120B-middle is used during algorithm design and data construction because it aligns relatively well with GPT-4.1 while being more computationally practical. Final HealthBench-Hard results use GPT-4.1 for comparability with the official protocol.
For rubric generation, DeepSeek-R1 and Gemini-2.5-Pro produce the most consistent improvements under GPT-OSS-120B-based evaluation. The default pipeline adopts DeepSeek-R1 as the rubric generator.
Data Integrity Diagnostics
The appendix examines semantic differences between HealthBench Consensus and HealthBench-Hard rubrics. Consensus rubrics form tighter clusters, while Hard rubrics are sparse and fragmented, reflecting greater constraint variability and reasoning difficulty.
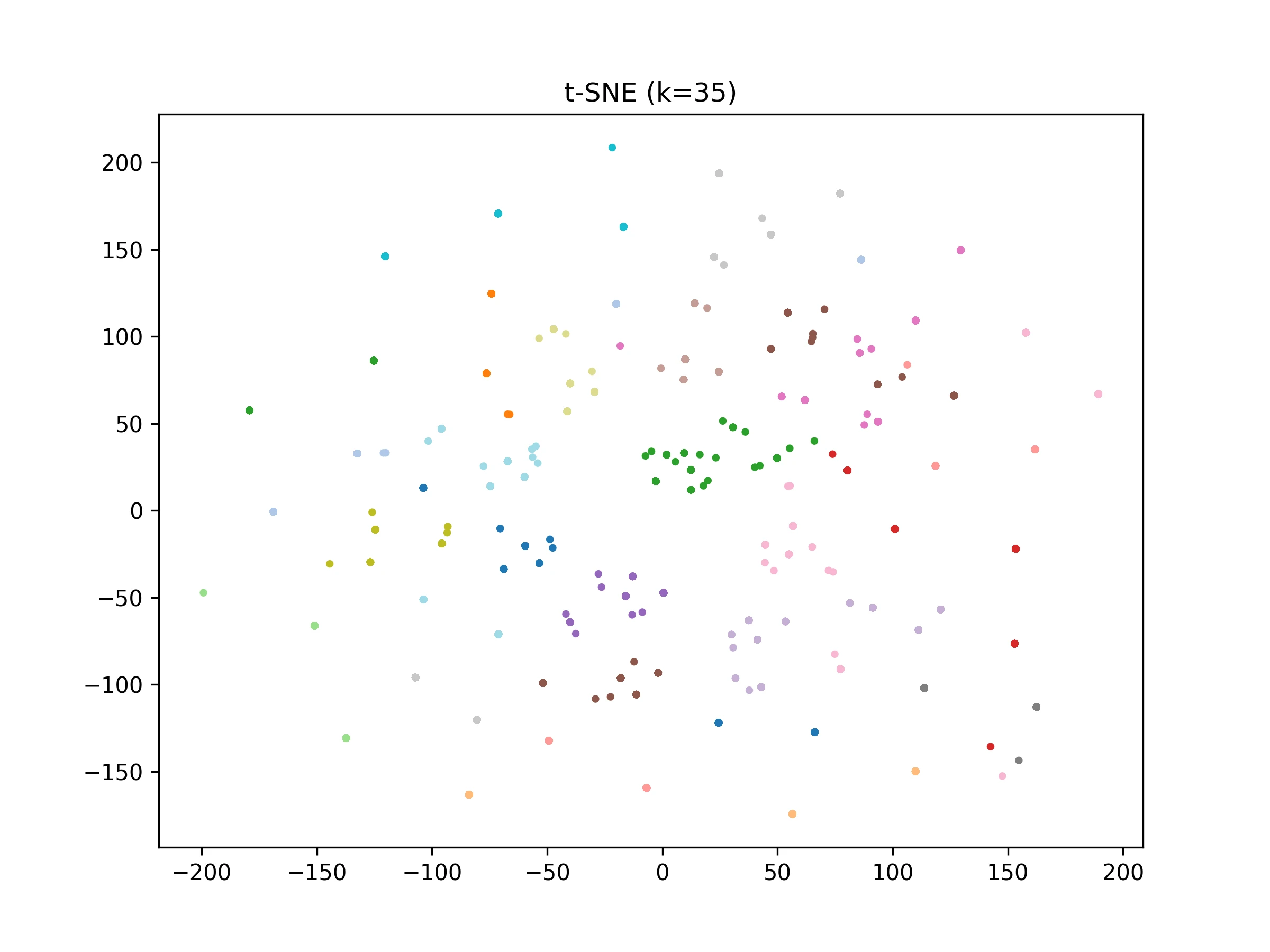
HealthBench Consensus rubrics form dense, cohesive clusters.
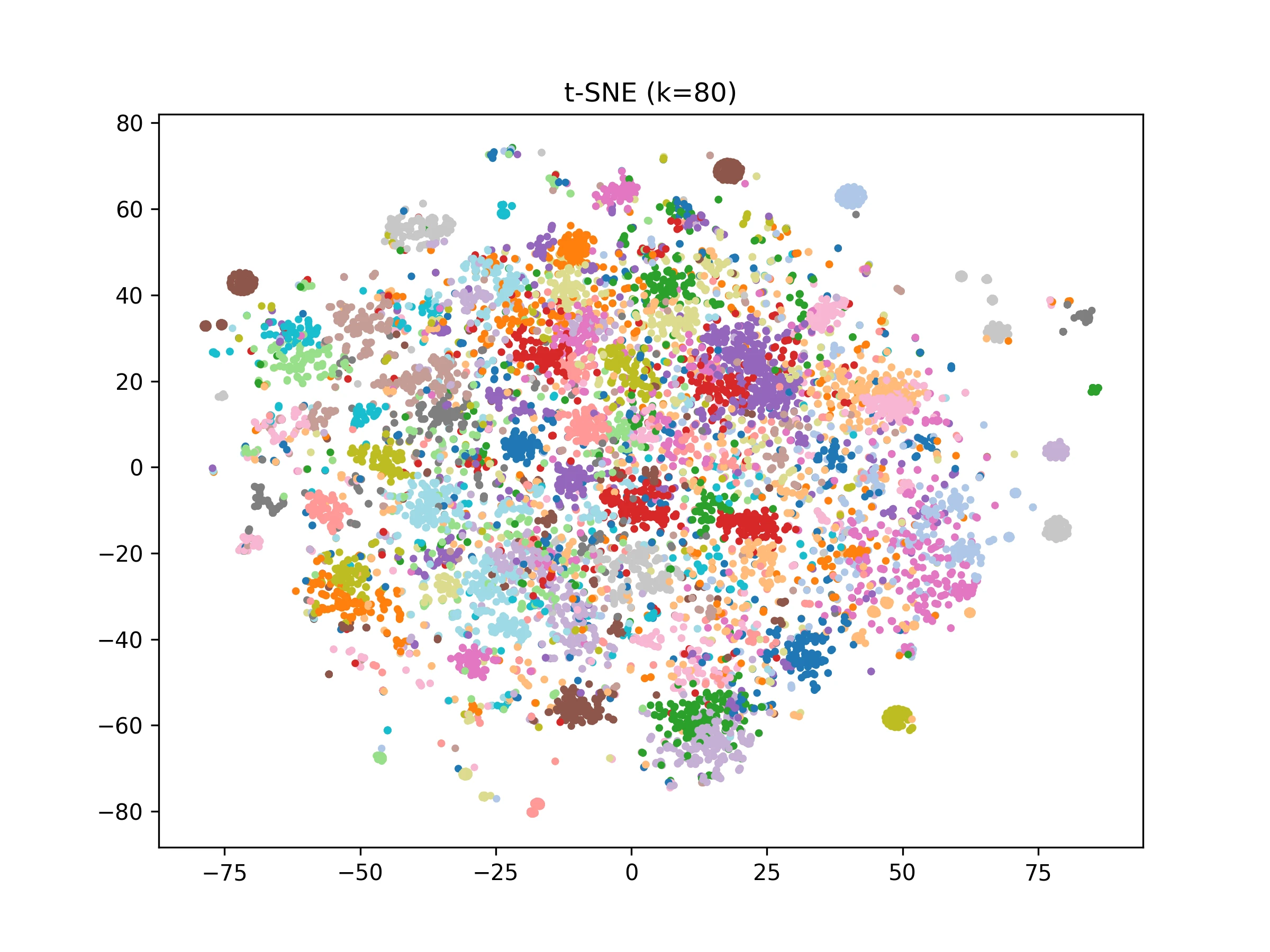
HealthBench-Hard rubrics show a sparse and fragmented topology.
The paper also performs prompt-level and rubric-level contamination diagnostics between NoHard and Hard data. High rubric similarity can reflect benign template reuse, so the joint prompt-rubric test is used to screen for instance leakage.
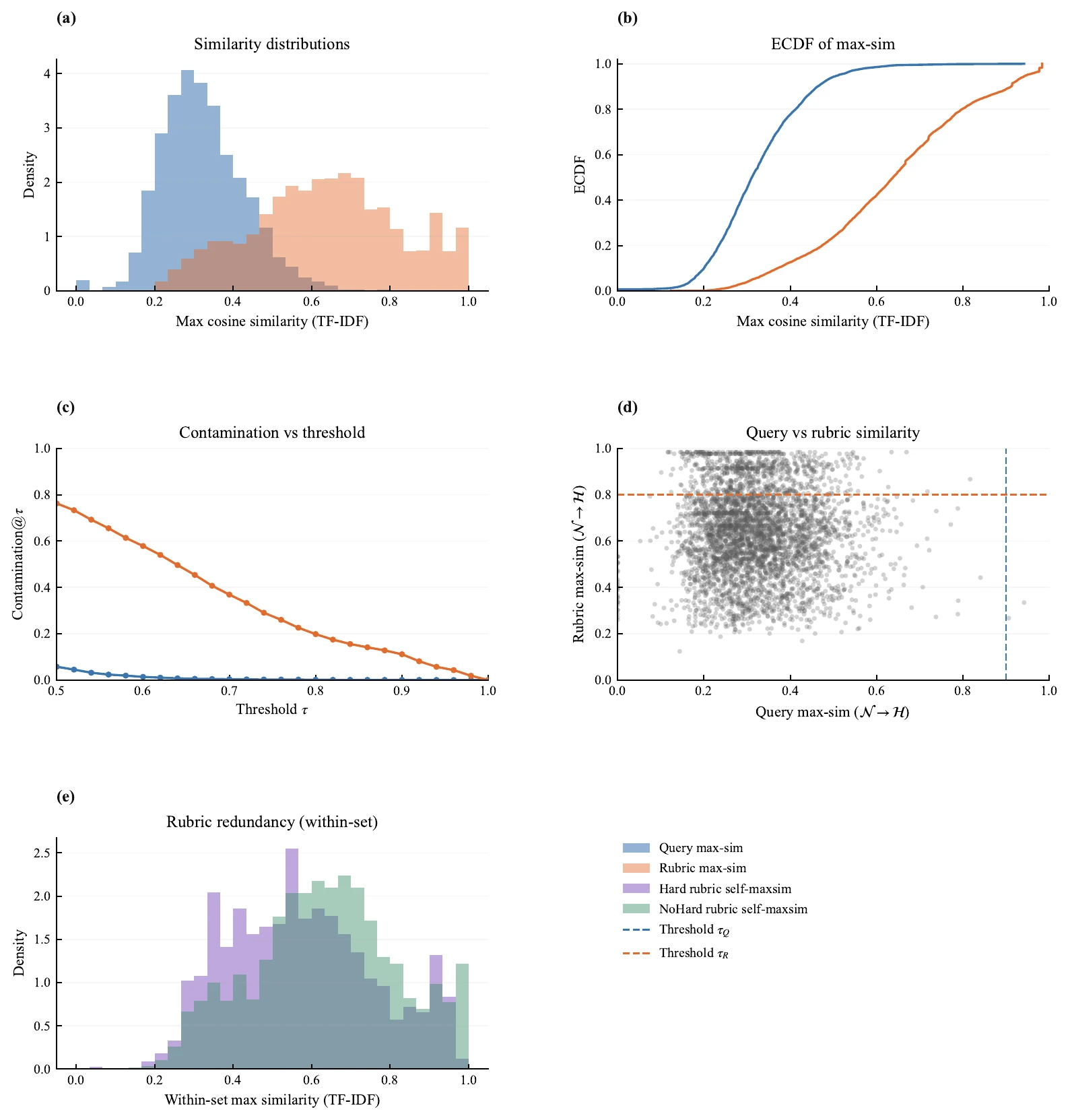
Prompt-rubric contamination diagnostics suggest high rubric similarity rarely co-occurs with near-duplicate prompts.
Impact Statement
Open-ended, high-stakes domains such as medical consultation require alignment methods that are reliable and interpretable. ORBIT translates qualitative clinical judgments into explicit training signals, improving data efficiency and controllability. It is not a substitute for clinical expertise, but it provides a practical step toward safer and more controllable alignment of language models in realistic medical dialogue settings.
Limitations
ORBIT still relies on a seed set of human-crafted rubrics. Generating seed rubrics from clinical guidelines and best practices is an important future direction. The experiments also fix Qwen3-30B-Instruct as the judge model during training; judge calibration and reasoning ability can vary across model families and scales, so judge-robust training remains important for deployment.
BibTeX
@misc{infimed-orbit-2026,
title={InfiMed-ORBIT: Aligning LLMs on Open-Ended Complex Tasks via Rubric-Based Incremental Training},
author={Anonymous},
year={2026},
url={},
}