InfiGUI-G1: Advancing GUI Grounding with Adaptive Exploration Policy Optimization
ABSTRACT
The emergence of Multimodal Large Language Models has propelled the development of autonomous GUI agents. A fundamental challenge is robustly grounding natural language instructions, requiring precise spatial alignment and, more critically, correct semantic alignment. We find that inefficient exploration bottlenecks semantic alignment in RLVR. We present Adaptive Exploration Policy Optimization (AEPO), which employs a multi-answer generation strategy guided by a theoretically grounded Adaptive Exploration Reward function. Our InfiGUI-G1-3B and InfiGUI-G1-7B establish new state-of-the-art results across multiple challenging GUI grounding benchmarks, achieving significant relative improvements of up to 9.0% against the naive RLVR baseline on benchmarks designed to test generalization and semantic understanding.
Abstract
The emergence of Multimodal Large Language Models (MLLMs) has propelled the development of autonomous agents that operate on Graphical User Interfaces (GUIs) using pure visual input. A fundamental challenge is robustly grounding natural language instructions. This requires a precise spatial alignment, which accurately locates the coordinates of each element, and, more critically, a correct semantic alignment, which matches the instructions to the functionally appropriate UI element. Although Reinforcement Learning with Verifiable Rewards (RLVR) has proven to be effective at improving spatial alignment for these MLLMs, we find that inefficient exploration bottlenecks semantic alignment, which prevent models from learning difficult semantic associations. To address this exploration problem, we present Adaptive Exploration Policy Optimization (AEPO), a new policy optimization framework. AEPO employs a multi-answer generation strategy to enforce broader exploration, which is then guided by a theoretically grounded Adaptive Exploration Reward (AER) function derived from first principles of efficiency . Our AEPO-trained models, InfiGUI-G1-3B and InfiGUI-G1-7B, establish new state-of-the-art results across multiple challenging GUI grounding benchmarks, achieving significant relative improvements of up to 9.0% against the naive RLVR baseline on benchmarks designed to test generalization and semantic understanding. Resources are available at https://github.com/InfiXAI/InfiGUI-G1.
Introduction
The development of autonomous agents capable of operating across the vast landscape of graphical user interfaces (GUIs) is a key frontier in achieving general-purpose human-computer interaction. The success of these agents is fundamentally predicated on a core perceptual task: GUI Grounding. This task involves accurately mapping a natural language instruction to a specific interactive element on a screen.
The challenge of GUI Grounding can be deconstructed into two orthogonal dimensions: Spatial Alignment, which focuses on the precision of locating an element (i.e., "pointing" accurately), as shown in the following figure (a). Semantic Alignment, which pertains to the correctness of identifying the appropriate element to interact with (i.e., "pointing" at the right target), as illustrated in the following figure (b). Robust and reliable agent performance in complex, real-world scenarios hinges on proficiency in both, with Semantic Alignment being particularly critical.

Figure 1: Primary GUI-grounding failure modes. (a) Spatial-alignment failure: the model selects the correct icon but localizes it imprecisely. (b) Semantic-alignment failure: the model localizes precisely on an incorrect icon due to misinterpreting the instruction. Although RLVR methods have advanced spatial alignment, semantic alignment remains the critical bottleneck for complex GUI tasks—this work is devoted to addressing it.
Current fine-tuning methodologies for multimodal large language models (MLLMs) face major challenges in achieving robust spatial alignment and semantic alignment. While Supervised Fine-Tuning (SFT) can be effective, it is highly data-intensive and struggles to generalize to unseen UI layouts. By contrast, Reinforcement Learning with Verifiable Rewards (RLVR) improves data efficiency by optimizing sequential coordinate generation, which has proven effective at enhancing spatial alignment.
However, most of existing RLVR methods share one limitation: inefficient exploration. They rely on the model's current policy to sample actions and thus get stuck on high-confidence errors. This "confidence trap" prevents discovery of low-probability but correct actions, bottlenecking semantic alignment. As shown in the figure above (b), when the instruction is "Use the camera to search for an object" on a screen displaying various icons, a model with weak semantic understanding may repeatedly select the generic "Camera" button. Standard RLVR would keep sampling this high-confidence but incorrect "Camera" icon, rarely stumbling upon the correct "Google Lens" icon, and thus fail to receive the learning signal necessary to correct its semantic misunderstanding.
We introduce Adaptive Exploration Policy Optimization (AEPO), a novel approach to overcome the exploration bottleneck in standard RL. By integrating the multi-answer generation strategy, AEPO drives the model to explore a diverse set of candidate solutions in a single forward pass, addressing the limitations of standard RL, which struggles with low sampling efficiency and the strategy confidence trap. Complemented through the adaptive exploration reward (AER), a non-linear reward signal, AEPO dynamically guides exploration, promoting exploration during failures and convergence upon successes, while avoiding the simplistic or distance-based rewards. Additionally, the quality-of-exploration penalty ensures high-quality exploration by penalizing inefficient, near-collinear outputs, fostering true semantic diversity rather than simplistic linear scans in the geometric space. In summary, the key contributions of our work are as follows:
- We present a novel policy-optimization method, Adaptive Exploration Policy Optimization (AEPO), which integrates multi-answer generation into the reinforcement learning framework to boost exploration efficiency for GUI grounding significantly.
- To balance the trade-off between exploration and exploitation, we devise an Adaptive Exploration Reward (AER) that incentivizes models to explore both extensively and purposefully.
- Building on the above framework, we introduce the InfiGUI-G1 series model—3B and 7B variants—whose extensive evaluation across diverse benchmarks establishes a state-of-the-art in the GUI grounding task.
Related Work
MLLM-based GUI Agents and Grounding
Recently, the paradigm for GUI automation has shifted gradually from brittle, script-based methods to visually driven, human-like approaches. A representative early attempt, OmniParser, utilizes an MLLM (e.g., GPT-4V) to parse visual UI elements in a screenshot into traditional structured data. OS-Atlas and U-Ground explored hybrid interfaces, intending to achieve robust and flexible performance across diverse environments. Notably, SeeClick firstly completed GUI tasks via relying solely on screenshots (visual input) and MLLMs, promising greater adaptability and cross-platform universality. However, its approach introduced a new task—GUI grounding—which has been identified as a key metric in this paradigm but also as a primary performance bottleneck.
To address GUI grounding, researchers have advanced a spectrum of techniques that enhance MLLMs' visual-locating capabilities. These include large-scale pre-training on GUI-specific corpora, targeted supervised fine-tuning (SFT), and reasoning-oriented frameworks. In parallel, novel training techniques have been adapted for MLLMs, including coordinate-free methods that generate attention maps instead of explicit coordinates, and inference-time optimization strategies that elevate performance without retraining.
Reinforcement Learning in MLLM
Reinforcement learning has rapidly become a potent paradigm for sharpening the reasoning capabilities of multimodal large language models. Building on the recent success of DeepSeek-R1 in large language models, a succession of vision-centric models, such as Vision-R1, Visual-RFT, MedVLM-R1, InfiMMR, demonstrated RL's broad potential across diverse domains.
In the context of GUI grounding, RL has demonstrated practical applicability through several notable approaches. UI-R1 introduces a novel rule-based action reward mechanism that enables model optimization using policy-based algorithms. GUI-R1 adopts a unified action space modeling strategy, which extracts and integrates action space categories across different platforms into a cohesive framework. Additionally, self-supervised and self-evolutionary RL methods have been proposed to address the limitations of traditional supervised fine-tuning (SFT), which often relies on large amounts of diverse labeled data. Reinforcement fine-tuning also shows promise as a pathway toward integrated training. R-VLM introduces a two-stage zoom-in grounding process that refines predictions through a zoomed-in view of region proposals. This is combined with an IoU-aware weighted cross-entropy loss to enhance fine-grained perception in grounding tasks. Overall, RL has proven to be an effective and efficient approach for training multi-modal large language models (MLLMs) and advancing GUI grounding performance.
Notably, these methods are constrained by a single-answer generation paradigm, which leads to inefficient exploration and can reinforce the model's confident but incorrect behaviors. In contrast, our framework employs multi-answer generation to enforce a broader search, which is then guided by our adaptive exploration reward function to provide richer and more effective learning signals.
Methodology
This section details our proposed AEPO framework. We first formalize the GUI grounding task as a policy optimization problem. We then elaborate on the core components of the AEPO framework, including multi-answer generation, the adaptive exploration reward, and the collinear penalty. Finally, we present the overall training objective.
Problem Formulation
We formulate GUI grounding as a direct policy optimization problem. The goal is to train a policy , represented by an MLLM with parameters , to generate an action that correctly corresponds to a given context.
- Context : A tuple , where is a GUI screenshot and is a natural language instruction.
- Action : The output generated by the policy, which is a coordinate point .
- Ground Truth : The ground truth bounding box of the target UI element corresponding to the instruction .
- Policy : The policy defines the probability distribution over all possible actions given a context .
- Reward Function : A deterministic function that returns a scalar reward. For a generated point , the reward is positive if and negative otherwise.
The objective is to find the optimal parameters that maximize the expected reward over the data distribution :
Because the action (i.e., the coordinate string) is generated auto-regressively, its sequential generation process is well-suited for optimization with policy gradient algorithms from reinforcement learning, such as Proximal Policy Optimization (PPO), Group Relative Policy Optimization (GRPO), or REINFORCE Leave-One-Out (RLOO).
Adaptive Exploration Policy Optimization
To overcome the exploration limitations of the standard formulation, we introduce a novel framework, namely Adaptive Exploration Policy Optimization (AEPO), as depicted in the following figure. AEPO enhances the policy optimization process through three synergistic components. The multi-answer generation mechanism enhances RL by improving exploration of suboptimal correct answers, overcoming low sampling efficiency and the strategy confidence trap. The adaptive reward function fosters exploration in response to failure while driving convergence upon success. The quality-of-exploration penalty improves exploration quality, ensuring that "multi-answer generation" promotes true diversity in the semantic space, beyond a mere linear scan in the geometric space.
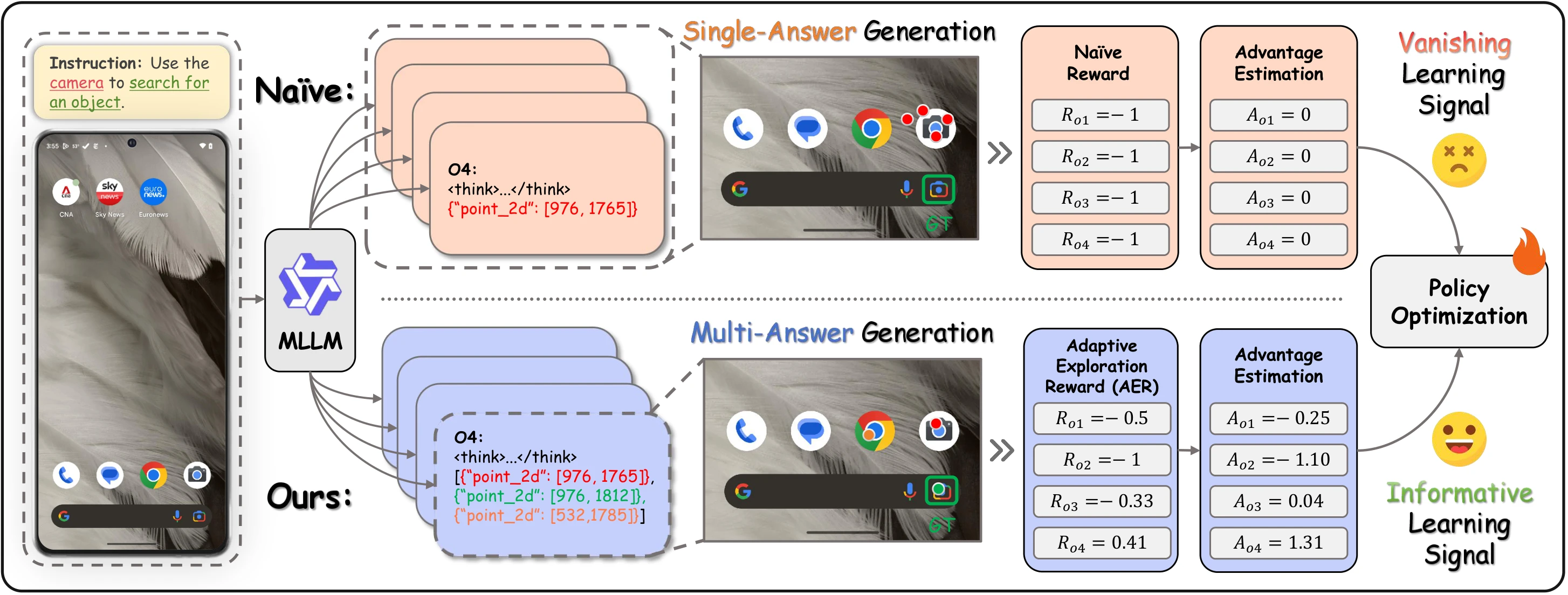
Figure 2: Comparison of AEPO and a naive RL baseline. Top: The naive single-answer approach becomes trapped on high-confidence errors, repeatedly sampling the same incorrect action and producing a vanishing learning signal when no positive reward is discovered. Bottom: AEPO employs multi-answer generation to explore diverse candidates each rollout and an AER to derive an informative learning signal from their efficiency and correctness. These mechanisms break the exploration bottleneck in GUI agents and enable robust semantic alignment.
Multi-Answer Generation. To fundamentally bypass the exploration bottleneck, our mechanism prompts the model to generate a set of candidate points, , in a single forward pass. This forces the model to look beyond its single most confident prediction, significantly increasing the probability of sampling a correct action from the tail of the policy's distribution, especially for semantically challenging samples.
Adaptive Exploration Reward.
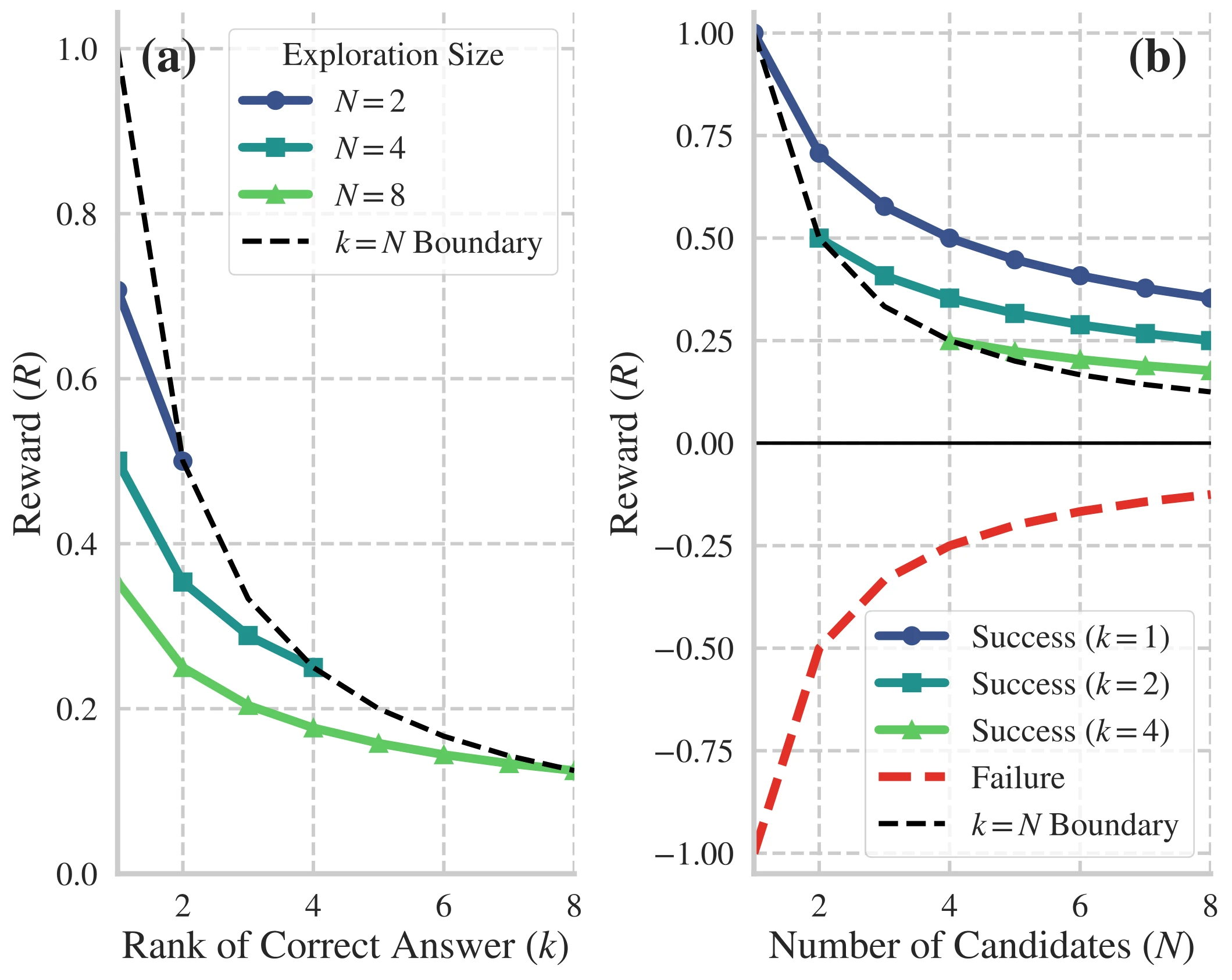
Figure 3: Visualization of the AER function based on the efficiency ratio . (a) The reward curve increases nonlinearly to strongly incentivize selection of the correct answer, i.e., lower rank . (b) The AER dynamically balances exploration and exploitation: successful trials (green/blue curves) receive higher reward for greater efficiency (smaller candidate set ), whereas failures (red curve) incur diminishing penalties to promote broader exploration.
AER provides an adaptive reward signal to guide the multi-answer exploration process. It is derived from a first-principles model of efficiency, , where is utility and is cost.
- Utility (): The utility is defined by the outcome of the exploration. If any point falls within the ground truth bounding box , the exploration is a success (). Otherwise, it is a failure (), reflecting not only the wasted computational resources but also the risk of guiding the agent into an erroneous state.
- Cost (): The cost is modeled as the geometric mean of two components. The proposal cost, , represents the effort to generate candidates. The verification cost, , represents the subsequent effort to identify the correct answer. We use the geometric mean, , as it appropriately captures the diminishing marginal returns of improving an already high-ranked answer. In case of success, (the rank of the first correct point), leading to . In case of failure, all points must be checked, so , and .
This leads to the AER function, which defines the accuracy component of our total reward:
This reward structure dynamically encourages wider exploration upon failure and rewards efficient, confident predictions upon success.
Collinear Penalty. To further improve the quality of exploration, we introduce a penalty for low-quality exploration strategies. If the set of generated points is found to be approximately collinear, we override the accuracy reward with a large negative value, . Collinearity is determined by checking if the area of the triangle formed by any three points in the set is close to zero. This discourages the model from adopting trivial, inefficient linear scanning strategies and incentivizes more spatially diverse exploration.
Overall Training Objective
The final reward signal for policy optimization combines a format reward with the accuracy reward . The format reward, which is +1 if the output string is correctly structured and 0 otherwise, serves as a prerequisite for any subsequent reward evaluation. The total reward is thus:
This total reward is then used to compute an advantage estimate, , which directly guides the update of the policy parameters. The complete training process is outlined in the following algorithm.
AEPO Training Loop
Initialize model parameters θ
for each training iteration do
Sample (S, I, B) from dataset D
Generate output sequence σ ~ π_θ(· | S, I)
R_format ← CheckFormat(σ)
R_accuracy ← 0
if R_format > 0 then
Extract N points A = {p_1, ..., p_N} from σ
if IsCollinear(A) then
R_accuracy ← -1
else
k ← FindFirstCorrectRank(A, B)
if k is not None then
R_accuracy ← 1 / sqrt(N · k)
else
R_accuracy ← -1 / N
end if
end if
end if
R_total ← R_format + R_accuracy
Calculate advantage estimate Â(σ, B) based on R_total
Update θ using policy gradient with advantage Â(σ, B)
end for
Experiments
Experimental Setup
Benchmarks and Metrics. We evaluate all models on five challenging benchmarks, each chosen to assess distinct capabilities. MMBench-GUI is a comprehensive benchmark with a hierarchical design of basic and advanced instructions, which we use to evaluate the overall effectiveness of our method across tasks of varying complexity. ScreenSpot-Pro is a benchmark designed to evaluate performance on high-resolution screens from professional software. Its distinct separation of text-based and icon-based grounding tasks provides a valuable setting to probe a model's semantic understanding, as icon grounding in particular requires associating abstract symbols with their functions. UI-Vision is designed to test generalization across a wide variety of desktop applications, assessing the model's robustness in diverse, unseen environments. Additionally, we report results on the widely-used ScreenSpot-v2 benchmark, which provides comprehensive coverage across mobile, desktop, and web platforms with a focus on both text and icon/widget elements. To further probe the semantic reasoning capabilities of the models, we also evaluate on UI-I2E-Bench. This next-generation benchmark was designed to overcome limitations of earlier datasets by including a higher proportion of implicit instructions that require semantic and spatial reasoning beyond direct text matching. Our primary evaluation metric is Accuracy, where a prediction is considered correct if its coordinate point falls within the ground truth bounding box. For methods that output a bounding box, its center point is used. To demonstrate the high success rate of our exploration strategy, we also report the Exploration Success Rate for our InfiGUI-G1 models, where a sample is marked as a success if at least one of the generated candidate points is correct.
Baselines. To ensure a fair and rigorous comparison, we establish two sets of baselines. First, for controlled analysis, we train a Naive RLVR model for both size as internal baselines. It is trained using the exact same dataset and optimized hyperparameters as our core models. Second, to position our work within the broader literature, we compare it against several state-of-the-art models from recent works.
Implementation Details. Our InfiGUI-G1 models are built upon the open-source Qwen2.5-VL-3B-Instruct and Qwen2.5-VL-7B-Instruct as backbones. For the RLVR training phase, we adopt the RLOO algorithm, which effectively reduces the variance of policy gradient estimates by employing the average reward of other samples within the same batch as a baseline. This "leave-one-out" strategy obviates the need for training a separate critic model. The RLOO policy gradient is estimated as:
where is the number of output sequences sampled from the policy given input . Across all experiments, we employ a reasoning prompting paradigm, instructing the model to generate its reasoning process within <think> </think> tags before providing the final answer.
Training Details. Our training data is a mixture sampled from several public GUI datasets, including Widget Caption, OmniAct, GUICourse, etc., resulting in approximately 44k samples. Following common practices in RLVR to focus training on more challenging instances, we apply a data filtering strategy: for each sample, we generate 8 responses with a temperature of 1.0; if all 8 are correct, the sample is deemed too easy and is excluded. All models were trained on 16 H800 GPUs. Key training parameters include a learning rate of 1e-6, a rollout batch size of 128, and an RLOO rollout number of . We train for 3 epochs.
Main Results
We present the main results of our evaluation in the following tables. The results consistently show that our InfiGUI-G1 models establish new state-of-the-art performance among open-source models in both the 3B and 7B parameter categories. Notably, our models also exhibit competitive or superior performance against several proprietary models with significantly larger parameter counts, highlighting the efficacy and efficiency of our proposed AEPO framework.
The comparison with our internal baselines reveals that InfiGUI-G1 consistently and substantially outperforms the Naive RLVR model across all benchmarks. This direct comparison suggests that the performance gains can be attributed to the architectural and methodological improvements introduced by AEPO. Furthermore, our models demonstrate strong performance against other SOTA methods, including those based on SFT (e.g., UGround, OS-Atlas), many of which require training data exceeding 1M samples. In contrast, our approach achieves these competitive results using 44k instances, underscoring its data efficiency. Our results also show strong performance against other RLVR approaches that utilize IoU or distance-based rewards (e.g., GUI-R1, GUI-G).
Our method demonstrates strong generalization capabilities by achieving consistently high performance across multiple benchmarks with distinct focuses (e.g., UI-Vision, ScreenSpot-Pro). Crucially, these benchmarks contain many applications and scenarios not present in our training data, indicating that AEPO fosters a robust understanding rather than overfitting. The benefits of AEPO in enhancing semantic understanding appear particularly pronounced on the ScreenSpot-Pro benchmark. Here, our models show a more substantial improvement on icon-based grounding tasks than on text-based ones when compared to the Naive RLVR baseline, suggesting that AEPO's enhanced exploration is especially beneficial for tasks requiring association of abstract visual symbols with their functions.
MMBench-GUI
Performance comparison on the MMBench-GUI benchmark. We report top-1 accuracy (%); for InfiGUI-G1 models, only the first generated answer is evaluated. Best and second-best results are shown in bold and underlined, respectively. For our models, we also report the Exploration Success Rate with the average number of generated candidates (Avg. N), and standard deviation over 5 runs.
| Model | Win. Basic | Win. Adv. | Mac Basic | Mac Adv. | Lin. Basic | Lin. Adv. | iOS Basic | iOS Adv. | And. Basic | And. Adv. | Web Basic | Web Adv. | Avg. | σ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4o | 1.5 | 1.1 | 8.7 | 4.3 | 1.1 | 1.0 | 5.1 | 3.3 | 2.5 | 1.4 | 3.2 | 2.9 | 2.9 | |
| Claude-3.7 | 1.5 | 0.7 | 12.5 | 7.5 | 1.1 | 0.0 | 13.7 | 10.6 | 1.4 | 1.4 | 3.2 | 2.3 | 4.7 | |
| Qwen-Max-VL | 43.9 | 36.8 | 58.8 | 56.1 | 53.9 | 30.1 | 77.4 | 59.1 | 79.5 | 70.1 | 74.8 | 58.8 | 58.0 | |
| ShowUI-2B | 9.2 | 4.4 | 24.1 | 10.4 | 25.1 | 11.7 | 29.0 | 19.7 | 17.4 | 8.7 | 22.9 | 12.7 | 16.0 | |
| Qwen2.5-VL-7B | 31.4 | 16.5 | 31.3 | 22.0 | 21.5 | 12.2 | 66.6 | 55.2 | 35.1 | 35.2 | 40.3 | 32.5 | 33.9 | |
| Qwen2.5-VL-72B | 55.7 | 33.8 | 49.9 | 30.1 | 40.3 | 20.9 | 56.1 | 28.2 | 55.6 | 25.4 | 68.4 | 45.8 | 41.8 | |
| OS-Atlas-Base-7B | 36.9 | 18.8 | 44.4 | 21.7 | 31.4 | 13.3 | 74.8 | 48.8 | 69.6 | 46.8 | 61.3 | 35.4 | 41.4 | |
| Aguvis-7B-720P | 37.3 | 21.7 | 48.1 | 33.3 | 33.5 | 25.0 | 67.5 | 65.2 | 61.0 | 51.0 | 61.6 | 45.5 | 45.7 | |
| UI-TARS-1.5-7B | 68.3 | 39.0 | 69.0 | 44.5 | 64.4 | 37.8 | 88.5 | 69.4 | 90.5 | 69.3 | 81.0 | 56.5 | 64.3 | |
| UI-TARS-72B-DPO | 78.6 | 51.8 | 80.3 | 62.7 | 68.6 | 51.5 | 90.8 | 81.2 | 93.0 | 80.0 | 88.1 | 68.5 | 74.3 | |
| UGround-V1-7B | 66.8 | 39.0 | 71.3 | 48.6 | 56.5 | 31.1 | 92.7 | 70.9 | 93.5 | 71.0 | 88.7 | 64.6 | 65.7 | |
| InternVL3-72B | 70.1 | 42.6 | 75.7 | 52.3 | 59.2 | 41.3 | 93.6 | 80.6 | 92.7 | 78.6 | 90.7 | 65.9 | 72.2 | |
| Naive RLVR-3B | 68.6 | 44.5 | 78.6 | 50.0 | 61.3 | 39.3 | 92.4 | 76.4 | 91.3 | 76.1 | 87.4 | 63.0 | 70.9 | |
| Naive RLVR-7B | 79.3 | 58.1 | 82.3 | 62.7 | 64.4 | 44.9 | 94.9 | 89.1 | 95.5 | 84.2 | 92.9 | 79.5 | 79.3 | |
| InfiGUI-G1-3B | 74.2 | 47.1 | 78.8 | 55.2 | 65.4 | 41.8 | 95.2 | 78.8 | 92.1 | 78.0 | 89.7 | 64.3 | 73.4 | 0.25 |
| w/ Expl. Success (Avg. N=2.0) | 79.7 | 59.9 | 86.4 | 66.8 | 73.3 | 54.1 | 97.1 | 87.0 | 96.3 | 88.7 | 95.2 | 75.6 | 81.6 | 0.41 |
| InfiGUI-G1-7B | 82.7 | 61.8 | 83.8 | 63.9 | 72.3 | 52.0 | 94.9 | 89.4 | 95.2 | 85.6 | 93.5 | 76.3 | 80.8 | 0.21 |
| w/ Expl. Success (Avg. N=1.6) | 87.1 | 69.1 | 87.2 | 76.3 | 78.5 | 58.2 | 98.1 | 92.4 | 98.0 | 91.8 | 97.1 | 85.7 | 86.4 | 0.11 |
ScreenSpot-Pro
Performance comparison on the ScreenSpot-Pro benchmark. We report Top-1 accuracy (%); for multi-answer models, only the first generated answer is evaluated. Best and second-best scores are shown in bold and underlined, respectively.
| Model | CAD Text | CAD Icon | Dev. Text | Dev. Icon | Crea. Text | Crea. Icon | Sci. Text | Sci. Icon | Off. Text | Off. Icon | OS Text | OS Icon | Avg. | σ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4o | 2.0 | 0.0 | 1.3 | 0.0 | 1.0 | 0.0 | 2.1 | 0.0 | 1.1 | 0.0 | 0.0 | 0.0 | 0.8 | |
| Claude Comp. Use | 14.5 | 3.7 | 22.0 | 3.9 | 25.9 | 3.4 | 33.9 | 15.8 | 30.1 | 16.3 | 11.0 | 4.5 | 17.1 | |
| SeeClick | 2.5 | 0.0 | 0.6 | 0.0 | 1.0 | 0.0 | 3.5 | 0.0 | 1.1 | 0.0 | 2.8 | 0.0 | 1.1 | |
| Qwen2-VL-7B | 0.5 | 0.0 | 2.6 | 0.0 | 1.5 | 0.0 | 6.3 | 0.0 | 3.4 | 1.9 | 0.9 | 0.0 | 1.6 | |
| CogAgent-18B | 7.1 | 3.1 | 14.9 | 0.7 | 9.6 | 0.0 | 22.2 | 1.8 | 13.0 | 0.0 | 5.6 | 0.0 | 7.7 | |
| UI-R1-3B | 11.2 | 6.3 | 22.7 | 4.1 | 27.3 | 3.5 | 42.4 | 11.8 | 32.2 | 11.3 | 13.1 | 4.5 | 17.8 | |
| ZonUI-3B | 31.9 | 15.6 | 24.6 | 6.2 | 40.9 | 7.6 | 54.8 | 18.1 | 57.0 | 26.4 | 19.6 | 7.8 | 28.7 | |
| GUI-R1-7B | 23.9 | 6.3 | 49.4 | 4.8 | 38.9 | 8.4 | 55.6 | 11.8 | 58.7 | 26.4 | 42.1 | 16.9 | 31.0 | |
| UI-TARS-7B | 20.8 | 9.4 | 58.4 | 12.4 | 50.0 | 9.1 | 63.9 | 31.8 | 63.3 | 20.8 | 30.8 | 16.9 | 35.7 | |
| UI-AGILE-7B | 49.2 | 14.1 | 64.3 | 15.2 | 53.0 | 9.8 | 72.9 | 25.5 | 75.1 | 30.2 | 45.8 | 20.2 | 44.0 | |
| GUI-G-7B | 55.8 | 12.5 | 68.8 | 17.2 | 57.1 | 15.4 | 77.1 | 24.5 | 74.0 | 32.7 | 57.9 | 21.3 | 47.5 | |
| Naive RLVR-3B | 36.0 | 18.8 | 63.0 | 15.2 | 49.5 | 13.3 | 65.3 | 26.4 | 64.4 | 32.1 | 39.3 | 16.9 | 39.8 | |
| Naive RLVR-7B | 53.8 | 17.2 | 71.4 | 15.9 | 60.6 | 11.9 | 76.4 | 26.4 | 74.6 | 34.0 | 54.2 | 20.2 | 47.6 | |
| InfiGUI-G1-3B | 50.8 | 25.0 | 64.9 | 20.0 | 51.5 | 16.8 | 68.8 | 32.7 | 70.6 | 32.1 | 49.5 | 15.7 | 45.2 | 0.13 |
| w/ Expl. Success (Avg. N=2.1) | 56.9 | 31.3 | 70.8 | 25.5 | 63.6 | 23.1 | 74.3 | 39.1 | 79.1 | 37.7 | 54.2 | 19.1 | 52.0 | 0.17 |
| InfiGUI-G1-7B | 57.4 | 23.4 | 74.7 | 24.1 | 64.6 | 15.4 | 80.6 | 31.8 | 75.7 | 39.6 | 57.0 | 29.2 | 51.9 | 0.48 |
| w/ Expl. Success (Avg. N=2.0) | 65.5 | 26.6 | 85.1 | 30.3 | 71.2 | 20.3 | 84.7 | 33.6 | 81.4 | 47.2 | 60.7 | 37.1 | 58.0 | 0.24 |
UI-Vision
Performance comparison on the UI-Vision benchmark. We report Top-1 accuracy (%).
| Model | Edu. | Browser | Dev. | Prod. | Creative | Entert. | Basic | Func. | Spatial | Overall | σ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4o | 1.5 | 0.0 | 2.2 | 1.1 | 0.8 | 4.2 | 1.6 | 1.5 | 1.0 | 1.4 | |
| Claude-3.7-Sonnet | 6.1 | 9.8 | 8.0 | 9.4 | 7.7 | 8.3 | 9.5 | 7.7 | 7.6 | 8.3 | |
| Qwen-2.5VL-7B | 0.5 | 0.0 | 1.2 | 0.9 | 0.5 | 1.0 | 1.2 | 0.8 | 0.5 | 0.9 | |
| InternVL2.5-8B | 1.1 | 7.0 | 3.0 | 1.8 | 1.2 | 5.2 | 2.5 | 2.8 | 1.0 | 2.1 | |
| MiniCPM-V-8B | 3.0 | 16.8 | 5.4 | 3.8 | 2.1 | 13.0 | 7.1 | 5.3 | 1.5 | 4.3 | |
| SeeClick-9.6B | 4.2 | 13.3 | 7.3 | 4.3 | 4.0 | 11.0 | 9.4 | 4.7 | 2.1 | 5.4 | |
| ShowUI-2B | 3.7 | 13.3 | 7.5 | 6.5 | 2.5 | 15.6 | 8.1 | 7.7 | 2.1 | 5.9 | |
| CogAgent-9B | 8.7 | 11.2 | 8.6 | 10.3 | 5.6 | 15.6 | 12.0 | 12.2 | 2.6 | 8.9 | |
| OSAtlas-7B | 8.7 | 16.8 | 10.3 | 9.2 | 5.6 | 16.2 | 12.2 | 11.2 | 3.7 | 9.0 | |
| AriaUI-25.3B | 9.0 | 18.9 | 11.2 | 10.4 | 6.5 | 19.3 | 12.2 | 14.0 | 4.0 | 10.1 | |
| UGround-v1-7B | 10.4 | 28.7 | 17.5 | 12.2 | 8.6 | 18.2 | 15.4 | 17.1 | 6.3 | 12.9 | |
| UGround-v1-72B | 22.4 | 35.7 | 27.6 | 21.6 | 18.3 | 38.0 | 27.9 | 26.7 | 14.9 | 23.2 | |
| Aguvis-7B | 13.1 | 30.8 | 17.1 | 12.1 | 9.6 | 24.0 | 17.8 | 18.3 | 5.1 | 13.7 | |
| UI-TARS-7B | 14.2 | 35.0 | 19.7 | 18.3 | 11.1 | 38.5 | 20.1 | 24.3 | 8.4 | 17.6 | |
| UI-TARS-72B | 24.8 | 40.5 | 27.9 | 26.8 | 17.8 | 41.1 | 31.4 | 30.5 | 14.7 | 25.5 | |
| Naive RLVR-3B | 18.5 | 37.8 | 21.8 | 19.6 | 12.8 | 42.7 | 27.4 | 24.6 | 7.3 | 19.4 | |
| Naive RLVR-7B | 23.5 | 42.7 | 27.4 | 24.5 | 16.2 | 50.5 | 32.9 | 30.7 | 10.1 | 24.1 | |
| InfiGUI-G1-3B | 22.6 | 43.4 | 24.3 | 22.6 | 14.0 | 47.4 | 31.2 | 28.0 | 8.2 | 22.0 | 0.20 |
| w/ Expl. Success (Avg. N=2.1) | 29.3 | 51.7 | 30.5 | 31.7 | 20.5 | 59.9 | 39.2 | 36.7 | 14.6 | 29.7 | 0.29 |
| InfiGUI-G1-7B | 25.5 | 46.2 | 29.6 | 26.7 | 17.6 | 52.1 | 36.2 | 31.9 | 11.5 | 26.1 | 0.05 |
| w/ Expl. Success (Avg. N=2.1) | 35.4 | 52.4 | 35.5 | 37.3 | 23.3 | 66.1 | 44.4 | 40.7 | 19.5 | 34.4 | 0.12 |
UI-I2E-Bench
Performance comparison on the UI-I2E-Bench benchmark. We report Top-1 accuracy (%).
| Model | Web | Desktop | Mobile | Explicit | Implicit | Overall | σ |
|---|---|---|---|---|---|---|---|
| Qwen2.5-VL-3B | 39.9 | 38.7 | 44.5 | 51.4 | 35.8 | 41.7 | |
| Qwen2.5-VL-7B | 56.9 | 41.6 | 61.7 | 58.4 | 51.0 | 53.8 | |
| Qwen2.5-VL-72B | 49.0 | 47.2 | 55.3 | 49.6 | 52.5 | 51.4 | |
| OS-Atlas-4B | 54.6 | 19.9 | 58.6 | 51.5 | 39.9 | 44.3 | |
| OS-Atlas-7B | 52.2 | 48.9 | 68.1 | 63.2 | 55.8 | 58.6 | |
| Aguvis-7B | 45.1 | 47.6 | 60.3 | 61.1 | 48.4 | 53.2 | |
| Uground-V1-2B | 66.4 | 49.5 | 59.9 | 72.9 | 47.9 | 57.4 | |
| Uground-V1-7B | 70.8 | 65.7 | 73.5 | 81.3 | 63.6 | 70.3 | |
| Uground-V1-72B | 74.7 | 74.6 | 78.2 | 84.5 | 71.3 | 76.3 | |
| UI-TARS-2B | 62.2 | 54.0 | 66.7 | 74.1 | 54.5 | 62.0 | |
| UI-TARS-7B | 56.5 | 58.0 | 65.7 | 71.4 | 55.3 | 61.4 | |
| UI-TARS-1.5-7B | 79.5 | 68.8 | 74.1 | 81.3 | 68.2 | 73.2 | |
| UI-TARS-72B | 77.1 | 69.8 | 75.5 | 80.9 | 69.4 | 73.7 | |
| UI-I2E-VLM-4B | 60.9 | 38.9 | 61.4 | 61.9 | 48.3 | 53.4 | |
| UI-I2E-VLM-7B | 62.1 | 64.0 | 76.2 | 72.0 | 67.9 | 69.5 | |
| UI-R1-E-3B | - | - | - | - | - | 69.1 | |
| Naive RLVR-3B | 74.7 | 62.0 | 78.9 | 81.3 | 65.8 | 71.6 | |
| Naive RLVR-7B | 83.0 | 63.0 | 77.6 | 84.8 | 70.2 | 75.8 | |
| InfiGUI-G1-3B | 79.8 | 60.7 | 78.9 | 81.1 | 67.5 | 72.6 | 0.30 |
| w/ Expl. Success (Avg. N=2.0) | 89.3 | 73.0 | 87.7 | 88.8 | 79.2 | 82.8 | 0.51 |
| InfiGUI-G1-7B | 84.6 | 66.3 | 83.0 | 85.0 | 72.7 | 77.4 | 0.40 |
| w/ Expl. Success (Avg. N=1.6) | 87.4 | 71.7 | 89.8 | 87.3 | 80.4 | 83.0 | 0.47 |
ScreenSpot-V2
Performance comparison on the ScreenSpot-V2 benchmark. We report Top-1 accuracy (%).
| Model | Mob. Text | Mob. Icon/Wid. | Desk. Text | Desk. Icon/Wid. | Web Text | Web Icon/Wid. | Avg. | σ |
|---|---|---|---|---|---|---|---|---|
| SeeClick | 78.4 | 50.7 | 70.1 | 29.3 | 55.2 | 32.5 | 55.1 | |
| OS-Atlas-Base-7B | 95.2 | 75.8 | 90.7 | 63.6 | 90.6 | 77.3 | 85.1 | |
| UI-TARS-7B | 96.9 | 89.1 | 95.4 | 85.0 | 93.6 | 85.2 | 91.6 | |
| UI-TARS-72B | 94.8 | 86.3 | 91.2 | 87.9 | 91.5 | 87.7 | 90.3 | |
| Qwen2.5-VL-3B | 93.4 | 73.5 | 88.1 | 58.6 | 88.0 | 71.4 | 80.9 | |
| Qwen2.5-VL-7B | 97.6 | 87.2 | 90.2 | 74.2 | 93.2 | 81.3 | 88.8 | |
| Qwen2.5-VL-32B | 97.9 | 88.2 | 98.5 | 79.3 | 91.2 | 86.2 | 91.3 | |
| Naive RLVR-3B | 99.3 | 86.3 | 93.3 | 80.7 | 94.0 | 79.8 | 90.1 | |
| Naive RLVR-7B | 99.0 | 91.5 | 94.8 | 80.7 | 96.6 | 85.2 | 92.5 | |
| InfiGUI-G1-3B | 99.3 | 88.2 | 94.8 | 82.9 | 94.9 | 80.3 | 91.1 | 0.05 |
| w/ Expl. Success (Avg. N=2.0) | 99.7 | 91.9 | 95.9 | 88.6 | 97.4 | 88.7 | 94.4 | 0.12 |
| InfiGUI-G1-7B | 99.0 | 91.9 | 94.3 | 82.1 | 97.9 | 89.2 | 93.5 | 0.09 |
| w/ Expl. Success (Avg. N=1.4) | 99.3 | 95.3 | 95.4 | 87.9 | 98.7 | 92.6 | 95.6 | 0.12 |
Ablation Studies
To dissect the contribution of each component within our AEPO framework, we conduct a series of ablation studies on the ScreenSpot-Pro benchmark. As its icon-based grounding tasks directly probe semantic understanding, this benchmark provides a clear setting to evaluate our design choices. The results are summarized in the following table.
Ablation study on the ScreenSpot-Pro benchmark. We compare model variants by Accuracy (%), Exploration Success Rate (%), and average number of answers per sample. Best results within each group are shown in bold.
| Model Configuration | Acc. | Expl. Succ. | # Answers |
|---|---|---|---|
| 3B Models | |||
| InfiGUI-G1 (Full Model) | 45.2 | 52.0 | 2.1 |
| w/o Multi-Answer (Naive) | 40.4 | - | 1.0 |
| w/o AER (use naive reward) | 38.4 | 42.1 | 1.9 |
| w/o AER's rank factor k | 38.1 | 47.6 | 2.5 |
| w/o Collinear Penalty | 35.3 | 44.1 | 6.6 |
| 7B Models | |||
| InfiGUI-G1 (Full Model) | 51.9 | 58.0 | 2.0 |
| w/o Multi-Answer (Naive) | 46.5 | - | 1.0 |
| w/o AER (use naive reward) | 41.4 | 45.5 | 1.9 |
| w/o AER's rank factor k | 44.0 | 50.5 | 1.9 |
| w/o Collinear Penalty | 37.0 | 43.8 | 8.2 |
The results reveal a clear logic behind AEPO's design. Removing multi-answer generation (w/o Multi-Answer) leads to a significant performance drop, confirming that enabling exploration is the necessary first step. However, this exploration must be guided effectively, as replacing our AER with a naive reward (w/o AER) causes a further decline. The importance of AER's ranking factor k is particularly insightful; removing it (w/o k) results in a model that often finds the correct answer (high Expl. Succ.) but fails to rank it first (low Acc.), demonstrating that k is crucial for teaching the model confidence in its correct discoveries. Finally, the collinear penalty proves essential for ensuring the quality of exploration. Without it, the model adopts a degenerate strategy of generating numerous low-quality answers (high # of answers) while accuracy plummets, showing the penalty is critical for preventing reward hacking.
Analysis of AEPO's Effectiveness
To further understand the mechanisms of AEPO, we conduct three targeted analyses.
Adaptive Exploration Strategy. We investigate if the model learns an adaptive exploration strategy. A clear correlation emerges between benchmark difficulty (indicated by model accuracy) and exploratory behavior. Our 7B model generates the most answers on the hardest benchmark (UI-Vision: 26.1% Acc, 2.1 answers) and the fewest on the easiest (ScreenSpot-V2: 93.5% Acc, 1.4 answers). This suggests AEPO learns to adaptively allocate exploratory resources based on task complexity.
Exploration Efficiency. We then evaluate the quality and efficiency of AEPO's exploration. Our InfiGUI-G1 models on ScreenSpot-Pro generate approximately two candidate answers per instance on average. To contextualize this, we compare our single-pass Exploration Success Rate against the multi-pass pass@k accuracy of the Naive RLVR baseline. As detailed in the following table, the results are compelling. Even when the Naive RLVR model is allowed four independent attempts (pass@4), its success rate in finding a correct answer is still significantly lower than that of our InfiGUI-G1, which achieves a higher success rate in a single pass with only about two attempts. This demonstrates that AEPO's multi-answer generation is not merely about increasing the number of tries, but about performing a more structured and efficient exploration of the action space.
Exploration efficiency (%) on ScreenSpot-Pro. Our single-pass success rate surpasses the baseline's multi-pass rate.
| Method | 3B Models | 7B Models |
|---|---|---|
| Naive RLVR (pass@2) | 41.7 | 49.8 |
| Naive RLVR (pass@4) | 43.5 | 52.1 |
| InfiGUI-G1 (Expl. Succ.) | 52.0 | 58.0 |
| ↪ Avg. N | 2.1 | 2.0 |
Performance on Hard-to-Explore Samples. Finally, to validate our core hypothesis that AEPO resolves the exploration bottleneck, we designed an experiment to analyze performance on samples of varying difficulty. We partitioned the ScreenSpot-Pro test set by first using the base MLLM to generate 16 stochastic responses for each sample. Samples were then labeled as hard if the base model failed all 16 times, easy if it succeeded every time, and middle otherwise. The hard subset therefore represents samples that are highly unlikely to be answered correctly through naive exploration. As shown in the following table, we then compared InfiGUI-G1 against the Naive RLVR baseline on these subsets. While our model improves performance across the board, the most significant gains are concentrated on the hard subset. On these critical samples, our 7B model achieves a relative improvement of over 60%. This provides direct evidence that AEPO effectively creates learning signals for previously "unlearnable" samples, addressing the fundamental limitation we set out to solve.
Accuracy (%) on ScreenSpot-Pro subsets of varying difficulty. AEPO's advantage is most significant on hard samples.
| Difficulty Subset | Naive RLVR (3B) | InfiGUI-G1 (3B) | Naive RLVR (7B) | InfiGUI-G1 (7B) |
|---|---|---|---|---|
| Easy | 100 | 100 | 100 | 100 |
| Middle | 75.9 | 78.9 (+4.0%) | 72.6 | 78.4 (+8.0%) |
| Hard | 25.5 | 31.4 (+23.1%) | 10.8 | 17.4 (+61.1%) |
Conclusion
In this work, we addressed the critical challenge of enhancing semantic alignment in MLLM-based GUI agents, identifying the inefficient exploration of standard RLVR as a key bottleneck. We proposed AEPO, a policy optimization framework that integrates multi-answer generation with a theoretically-grounded AER function to enable effective exploration. Our model, InfiGUI-G1, achieves state-of-the-art performance, and our comprehensive analyses confirm that its effectiveness stems from its ability to adapt its exploration strategy, its high efficiency compared to naive sampling, and its success in creating learning signals for previously "unlearnable" samples.
Limitations of our work include the computational overhead from multi-answer generation and a performance ceiling imposed by the backbone MLLM's visual capabilities, which could be addressed in future work by exploring more efficient sampling strategies and integration with more advanced visual encoders.
BibTeX
@misc{liu2025infiguig1advancingguigrounding,
title={InfiGUI-G1: Advancing GUI Grounding with Adaptive Exploration Policy Optimization},
author={Yuhang Liu and Zeyu Liu and Shuanghe Zhu and Pengxiang Li and Congkai Xie and Jiasheng Wang and Xueyu Hu and Xiaotian Han and Jianbo Yuan and Xinyao Wang and Shengyu Zhang and Hongxia Yang and Fei Wu},
year={2025},
eprint={2508.05731},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2508.05731},
}