InfiFPO: Implicit Model Fusion via Preference Optimization in Large Language Models
ABSTRACT
Model fusion combines multiple LLMs with different strengths into a more powerful model through lightweight training. Existing works focus primarily on supervised fine-tuning, leaving preference alignment largely unexplored. InfiFPO replaces the reference model in DPO with a fused source model that synthesizes multi-source probabilities at the sequence level, circumventing vocabulary alignment challenges while preserving probability information. With probability clipping and max-margin fusion strategies, InfiFPO enables the pivot model to align with human preferences while distilling knowledge from source models. When using Phi-4 as the pivot model, InfiFPO improves its average performance from 79.95 to 83.33 on 11 benchmarks, significantly improving its capabilities in mathematics, coding, and reasoning tasks.
Abstract
Model fusion combines multiple Large Language Models (LLMs) with different strengths into a more powerful, integrated model through lightweight training methods. Existing works on model fusion focus primarily on supervised fine-tuning (SFT), leaving preference alignment (PA)—a critical phase for enhancing LLM performance—largely unexplored.
The current few fusion methods on PA phase, like WRPO, simplify the process by utilizing only response outputs from source models while discarding their probability information. To address this limitation, we propose InfiFPO, a preference optimization method for implicit model fusion.
InfiFPO replaces the reference model in Direct Preference Optimization (DPO) with a fused source model that synthesizes multi-source probabilities at the sequence level, circumventing complex vocabulary alignment challenges in previous works and meanwhile maintaining the probability information. By introducing probability clipping and max-margin fusion strategies, InfiFPO enables the pivot model to align with human preferences while effectively distilling knowledge from source models.
Comprehensive experiments on 11 widely-used benchmarks demonstrate that InfiFPO consistently outperforms existing model fusion and preference optimization methods. When using Phi-4 as the pivot model, InfiFPO improves its average performance from 79.95 to 83.33 on 11 benchmarks, significantly improving its capabilities in mathematics, coding, and reasoning tasks.
Introduction
Large Language Models (LLMs) have demonstrated impressive capabilities across a wide range of natural language tasks. Yet, no single model is universally optimal—different LLMs often possess distinct strengths due to variations in architecture, pretraining data, and objectives. This has motivated a surge of interest in model fusion, which aims to integrate knowledge from multiple source models into a single pivot model to enhance its overall performance.
While existing work on model fusion has primarily focused on the supervised fine-tuning (SFT) phase, little attention has been paid to integrating fusion techniques into the preference alignment phase, a critical step in reinforcement learning from human feedback (RLHF) pipelines that substantially boosts performance and usability. Applying model fusion to this phase is non-trivial due to the discrete nature of preference data and the challenge of aligning both preferred and dispreferred outputs across heterogeneous models.
The closest prior work, WRPO, attempts to bridge this gap by incorporating high-quality source model responses as additional preference signals. However, WRPO suffers from two major limitations: (1) it discards the probabilistic outputs of source models and only uses response-level supervision; and (2) it focuses solely on preferred responses, missing valuable contrastive signals for dispreferred ones. As a result, WRPO only partially leverages the capabilities of the source models. The broader question—how to systematically fuse model knowledge during preference alignment—remains largely unanswered.
To overcome these limitations, we propose InfiFPO, a principled and efficient framework for performing model fusion during the preference alignment phase. Our key insight is that the reference model in preference optimization (e.g., in DPO) can be replaced with a fused source model, thereby enabling the pivot model to learn not only from preference data but also from the probabilistic behaviors of multiple source models. Unlike WRPO, InfiFPO utilizes sequence probability from all source models—including for both preferred and dispreferred responses—making the fusion process more principled and information-rich. We call this fusion that utilizes sequence-level probabilities as implicit model fusion, distinguishing it from previous work on token-level model fusion.
To instantiate InfiFPO efficiently, we derive it from an RLHF-style constrained optimization framework called FuseRLHF, which encourages the pivot model to maximize preference rewards while remaining close—in sequence-level KL divergence—to each source model. We further transform this constrained RL problem into a fully offline optimization objective that avoids expensive online sampling and reward model training.
To improve the robustness and effectiveness of InfiFPO, we introduce three key enhancements: (1) Length Normalization, which reduces bias arising from varying token sequence lengths across models; (2) Probability Clipping, which limits the influence of underperforming source models by suppressing noisy gradients; and (3) Max-Margin Fusion, which adaptively prioritizes source models that offer the most distinctive and informative deviations from the pivot model.
We conducted a comprehensive evaluation of InfiFPO using Phi-4 as the pivot model and selecting five mainstream open-source LLMs with parameters ranging from 9B to 24B as source models. Our experiments spanned 11 widely-used benchmarks covering diverse tasks, including mathematics, coding, instruction following, and so on. Results demonstrate that InfiFPO consistently outperforms existing model fusion and preference optimization methods, improving Phi-4's average performance from 79.95 to 83.33 across 11 benchmarks. Furthermore, InfiFPO exhibits great versatility, effectively combining with various preference optimization objectives to further enhance performance.
In summary, our contributions are threefold:
- We propose InfiFPO, a novel preference optimization framework that performs implicit model fusion by replacing the reference model in DPO with a fused source model, derived via an offline relaxation of a sequence-KL constrained RLHF objective.
- We introduce three stability-enhancing strategies—length normalization, probability clipping, and max-margin fusion—to avoid degradation from tokenization mismatch and probability inconsistencies in source models.
- We conduct extensive experiments on 11 preference benchmarks, demonstrating that InfiFPO consistently and significantly outperforms existing model fusion and preference optimization baselines, verifying its effectiveness for implicit model fusion.
Preliminaries
In this section we briefly revisit the two foundations of our work: Model Fusion and Direct Preference Optimization (DPO).
Model Fusion
The goal of model fusion is to integrate knowledge from source models with different architectures, parameter sizes, and training data into one pivot model to enhance the pivot model's capabilities. Given source models and a pivot model (also called target model) , the model fusion can be cast as a KL-constrained optimization problem:
where each sample in the dataset contains a prompt sequence and its corresponding response sequence . indicates token-level KL divergence. Each constraint keeps the pivot model within an -ball of every source model, thereby fusing their behaviors. While effective, this formulation suffers from vocabulary conflict: the source models often employ incompatible tokenizers, forcing previous work to rely on heuristic vocabulary matching.
Direct Preference Optimization
DPO is an offline replacement for Reinforcement Learning from Human Feedback (RLHF). The objective of RLHF can be formalized as:
where is a reward model that evaluates how good the response generated by policy model is. indicates sequence-level KL divergence. Usually, the base reference model is the initial , and is a parameter controlling the deviation from .
After deriving the relationship between and the optimal policy :
Since the reference model remains unchanged during training, the optimal policy model is theoretically determined only by the reward model . A natural idea is to indirectly train the optimal policy model through training the reward model, which is the optimization objective of DPO:
where each sample in the preference dataset contains a prompt , a preferred response , and a dispreferred response .
InfiFPO: Preference Optimization for Model Fusion
This section presents InfiFPO, our novel approach to preference optimization for Model Fusion. We begin by introducing the FuseRLHF objective, which integrates model fusion with RLHF. Given the inherent complexity of reinforcement learning frameworks, direct implementation proves challenging. Consequently, we propose an efficient offline InfiFPO methodology and develop three performance-enhancing strategies. Finally, we provide gradient analysis to further understand the optimization mechanism of InfiFPO.
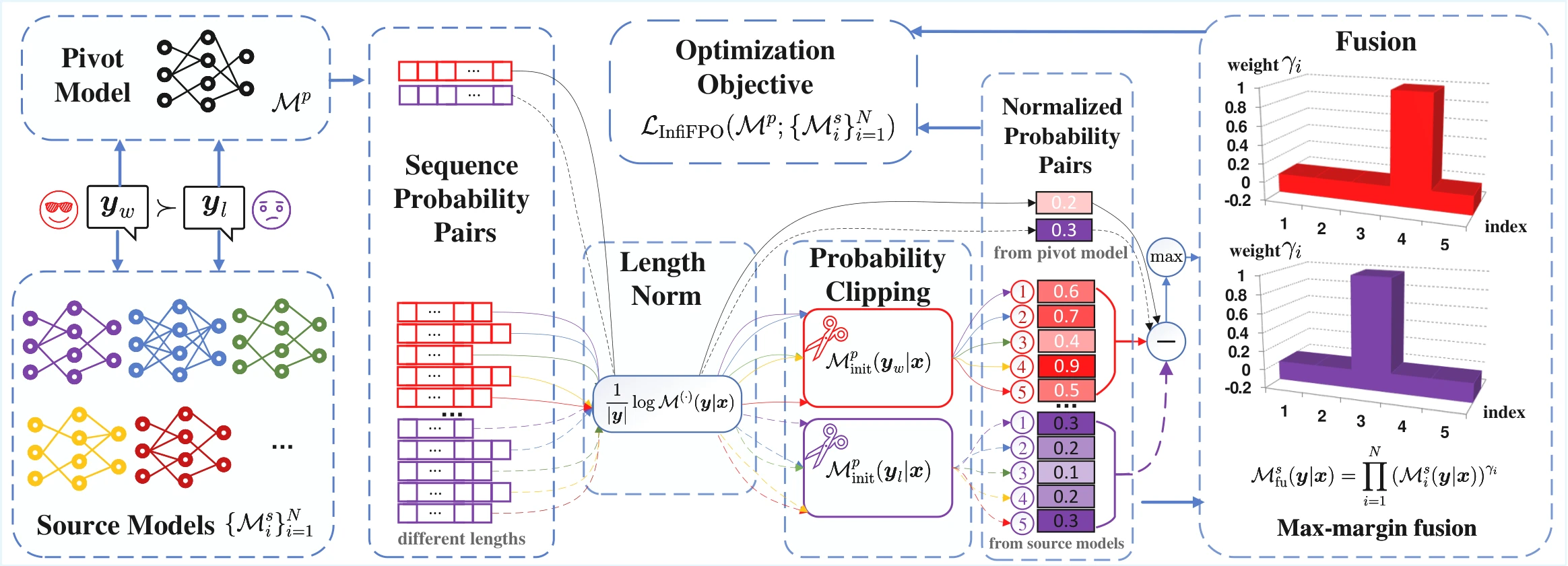
Overview of InfiFPO for implicit model fusion. We compute probabilities for preferred and dispreferred responses using both pivot and source models. Following length normalization and probability clipping, we identify the source model with the maximum normalized probability difference from the pivot model for fusion and preference alignment.
FuseRLHF: RLHF for Implicit Model Fusion
Constrained objective. We consider model fusion during the preference alignment phase to be a constrained optimization problem. Combining the model fusion and RLHF objectives, we obtain:
where the initial pivot model is included in the source models. Each constraint keeps the pivot policy within an -ball (in KL divergence) of every teacher, thereby fusing their behaviour while still allowing preference alignment through the reward .
Please note that we use KL constraints at the sequence level instead of the token level. Previous works on model fusion used token-level KL and faced the vocabulary conflict issue, where heterogeneous models have different vocabularies, making their token-level output distributions incompatible for divergence calculation. To solve this issue, those works introduce complex vocabulary matching processes and only calculate KL divergence on the matching portions. In contrast, our sequence-level KL constraints avoid this issue while preserving the source models' probability information, learning source models' preferences for the whole sentence. We call this fusion that utilizes sequence-level probabilities as implicit model fusion (IMF).
Unconstrained objective. Introducing non-negative multipliers and relaxing the constraints yields:
where and . When and taking the source model as the initial pivot model, this reduces to classical RLHF.
InfiFPO: Efficient Preference Optimization for IMF
Deriving the FPO objective. Directly training the pivot model with FuseRLHF requires significant time and resources. On one hand, it requires training an additional reward model; on the other hand, during RL, the pivot model needs to sample responses online, while all source models also need to calculate sequence probabilities simultaneously. To reduce these costs, we convert online FuseRLHF to offline InfiFPO, improving training efficiency. Following prior works, it is clear to show that the optimal pivot model to the FuseRLHF objective takes the form:
where a fused source model and a partition function . We can rearrange to show the relationship between the reward model and the optimal pivot model:
We can see that theoretically the optimal pivot model only depends on the reward model , since the source models remain unchanged during training. Therefore, we can derive the optimization objective of FPO as follows:
Especially, when and using the initial pivot model as the source model, this loss function reduces to original DPO. While the FPO objective is simple and theoretically supported, it faces length normalization and source model degradation issues in model fusion. Besides, the fusion multipliers for source models requires a strategy for determination. To address these issues, we propose the following three strategies.
Length Normalization. Models with larger vocabularies tend to produce longer segmentations whose log-likelihood sums are lower, even when the semantic adequacy of the response is unchanged. To address the length bias issue, we introduce the length normalization, which divides the sequence log probability from a model by the length of the sequence after tokenization with that model:
Probability Clipping. Source models may occasionally assign lower probability to the preferred response (or higher probability to the dispreferred response ) than the pivot model, injecting misleading gradients and causing instability. To avoid the source model degradation issue, we clip the sequence probabilities of the source model. Specifically, for , we define the minimum probability of the source model as the sequence probability of the initial pivot model ; for , we define the maximum sequence probability of the source model as the sequence probability of the initial pivot model.
This piecewise definition is weakly monotone: for all we have , so the logarithm that follows preserves (or ties) the order of probabilities and cannot invert preferences.
Max-Margin Fusion. To determine the multipliers for source models, we propose a max-margin fusion strategy that maximizes the diversity of information incorporated into the pivot model. Specifically, we select the source model that differs most from the current pivot model, as this model likely contains the most unique and complementary information.
where measures the probability difference between a source model and the pivot model. This winner-takes-all approach simplifies training while effectively capturing diverse capabilities across source models.
Final Objective. Combining the strategies listed above, we have the final InfiFPO objective:
where .
Gradient Analysis
To gain deeper insights into InfiFPO's optimization dynamics, we analyze the gradient of the loss function with respect to the pivot model parameters . This analysis elucidates how information from source models influences the pivot model's learning trajectory. The gradient can be expressed as:
where and . Analogous to DPO, the InfiFPO gradient increases the likelihood of preferred responses while decreasing that of dispreferred responses . However, the critical distinction lies in the preference disparity coefficient, which weights training samples based on the divergence between the source and pivot models' preference assessments. This coefficient becomes larger when source models exhibit a stronger preference between and than the pivot model does. Consequently, samples where the source models strongly differentiate between responses but the pivot model does not yet reflect this distinction receive greater optimization emphasis. This adaptive weighting mechanism efficiently transfers preference knowledge from source models to the pivot model.
Experiments
Setup
Model. We use Phi-4 as the pivot model. The source models consist of three general-purpose models (Qwen2.5-14B-Instruct, Mistral-Small-24B-Instruct, and Gemma-3-12B-Instruct) and two domain-specific models (Qwen2.5-Coder-14B-Instruct and Qwen2.5-Math-7B-Instruct). By including these domain-specific models as additional source models, we can also investigate whether specialized expertise can enhance the overall performance of general models. Domain-specific models Qwen-Coder and Qwen-Math perform poorly outside their specialized domains; to prevent these limited capabilities from being fused into the pivot model, we selectively fused Qwen-Coder only on code data and Qwen-Math only on mathematical data.
Dataset. We constructed a new training dataset comprising 150k examples across mathematics, coding, and general tasks:
| Types | General Data | Math Data | Code Data |
|---|---|---|---|
| Dataset | Infinity-Instruct | NuminaMath-1.5 | KodCode-V1-SFT |
| Original Size | 1.4M | 1.4M | 268k |
| Sample Size | 60K | 45K | 45K |
Since the original dataset may contain responses from outdated LLMs, potentially less capable than our pivot model, we retained only the prompts to build a new preference dataset. For each prompt, we generated responses using multiple models: 4 from each source model and 8 from the pivot model, all with a sampling temperature of 0.8. We then employed a reward model (Skywork-Reward-Gemma-2-27B) to evaluate these responses, selecting the highest-scored response as and the lowest-scored as .
Training Detail. Training involved two stages with a batch size of 128 and maximum sequence length of 4,096 tokens, using 16 NVIDIA A800-80GB GPUs. We implemented a cosine learning rate schedule with a 10% warmup ratio. In the first stage, SFT on half of the dataset with for 3 epochs (learning rate 1e-6). This model then served as the foundation for the second stage, where we conducted preference optimization on the remaining half for a single epoch (learning rate 1e-7, ).
Evaluation. We conduct a comprehensive evaluation across 11 diverse benchmarks to assess the model's capabilities. Our evaluation spans five critical dimensions: (1) General reasoning (BBH, ARC-C, MMLU), (2) Math (GSM8K, MATH, TheoremQA), (3) Code (MBPP, HumanEval), (4) Text reasoning (DROP, HellaSwag), and (5) Instruction following (IFEval). This multifaceted evaluation strategy enables us to systematically analyze the model's strengths and limitations across a spectrum of tasks requiring different cognitive abilities.
Baseline. We compare InfiFPO with three categories of baselines, including pivot & source models, model fusion methods, and preference optimization methods. For model fusion methods, we include FuseLLM, FuseChat, and InfiFusion. Limited by the complex vocabulary alignment and distribution merging process, we only include Qwen2.5-Instruct, Qwen2.5-Coder, and Mistral-Small as source models for fusion baselines. For fair comparison, we select the same source models to implement InfiFPO (marked with asterisks). For preference optimization methods, we include DPO, IPO, and WRPO. All these preference optimization methods adopt the same two-stage training approach as InfiFPO, i.e., first using half of the data for SFT, then using the remaining half for preference optimization.
Main Results
| Models | GSM8K | MATH | ThmQA | MBPP | HEval | BBH | ARC | MMLU | IFEval | DROP | HS | Avg | Size | GPU Hrs |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pivot: Phi-4 | 87.41 | 80.04 | 51.12 | 75.40 | 83.54 | 68.84 | 93.90 | 85.62 | 77.34 | 88.67 | 87.62 | 79.95 | 14B | ~1.0M |
| Qwen2.5-Instruct | 91.13 | 78.16 | 47.25 | 81.70 | 83.54 | 77.59 | 92.20 | 80.22 | 85.01 | 85.56 | 88.28 | 80.97 | 14B | ~1.8M |
| Mistral-Small | 92.42 | 69.84 | 48.50 | 68.80 | 84.15 | 81.59 | 91.86 | 81.69 | 82.25 | 86.52 | 91.84 | 79.95 | 24B | ~1.6M |
| Qwen2.5-Coder | 89.16 | 74.18 | 38.88 | 85.40 | 90.90 | 75.40 | 89.49 | 75.08 | 74.70 | 84.34 | 79.83 | 77.94 | 14B | ~1.8M |
| Gemma-3-Instruct | 93.71 | 82.90 | 49.62 | 72.60 | 82.32 | 85.70 | 71.19 | 77.61 | 90.77 | 86.43 | 83.34 | 79.65 | 12B | - |
| Qwen2.5-Math | 92.27 | 81.70 | 20.25 | 1.40 | 46.34 | 33.12 | 65.76 | 40.20 | 35.49 | 81.96 | 25.57 | 47.64 | 7B | ~0.5M |
| Fusion Methods | ||||||||||||||
| FuseLLM* | 90.24 | 80.25 | 53.52 | 79.28 | 84.00 | 77.62 | 92.08 | 83.92 | 78.56 | 88.74 | 87.81 | 81.46 | 14B | 225 |
| FuseChat* | 91.21 | 77.52 | 51.88 | 81.80 | 84.15 | 83.37 | 93.56 | 84.23 | 78.90 | 89.23 | 87.42 | 82.12 | 14B | 650 |
| InfiFusion* | 90.07 | 80.94 | 55.62 | 81.80 | 83.54 | 80.94 | 94.24 | 85.81 | 76.02 | 89.27 | 87.91 | 82.38 | 14B | 160 |
| PO Methods | ||||||||||||||
| SFT | 88.70 | 79.58 | 55.12 | 78.20 | 86.59 | 74.66 | 93.56 | 84.36 | 80.06 | 88.72 | 87.75 | 81.57 | 14B | 15 |
| SFT-DPO | 89.76 | 80.02 | 57.88 | 82.50 | 84.76 | 77.86 | 94.58 | 84.27 | 81.89 | 88.56 | 87.31 | 82.67 | 14B | 50 |
| SFT-IPO | 90.45 | 80.18 | 55.25 | 82.50 | 85.37 | 77.13 | 94.24 | 84.08 | 80.94 | 88.67 | 87.36 | 82.38 | 14B | 50 |
| SFT-WRPO | 89.92 | 80.02 | 57.88 | 83.10 | 86.59 | 78.18 | 94.24 | 83.98 | 81.18 | 88.41 | 87.30 | 82.80 | 14B | 57 |
| InfiFPO | ||||||||||||||
| InfiFPO* | 89.92 | 79.88 | 57.00 | 82.00 | 85.98 | 81.26 | 94.24 | 83.33 | 80.46 | 88.68 | 87.36 | 82.74 | 14B | 55 |
| InfiFPO | 90.07 | 80.10 | 57.25 | 82.50 | 87.80 | 82.02 | 94.24 | 84.27 | 82.25 | 88.83 | 87.29 | 83.33 | 14B | 58 |
* indicates only Qwen2.5-Instruct, Qwen2.5-Coder, and Mistral-Small as source models. Abbreviations: ThmQA (TheoremQA), HEval (HumanEval), HS (HellaSwag).
Key findings:
- InfiFPO effectively integrates the capabilities of the source models. InfiFPO significantly improved the pivot model's average performance across 11 benchmarks from 79.95 to 83.33. This integration is particularly remarkable as InfiFPO manages to inherit specialized strengths from diverse source models, such as mathematical reasoning from Qwen2.5-Math and code generation from Qwen2.5-Coder, while avoiding their respective weaknesses. For instance, while Qwen2.5-Math excels on GSM8K and MATH (92.27 and 81.70) but performs poorly on other tasks, and Qwen2.5-Coder achieves top scores on MBPP and HumanEval (85.40 and 90.90) but underperforms on theorem questions, InfiFPO maintains balanced high performance across these diverse task categories.
- InfiFPO outperforms model fusion baselines in both efficiency and effectiveness. Compared to InfiFusion*, the best-performing baseline on average, InfiFPO* shows an average improvement of 0.36 across 11 benchmarks. The improvements are particularly significant for instruction-following and code tasks, with a 4.4 improvement on IFEval and a 2.4 improvement on HumanEval. More importantly, InfiFPO* requires only 34% of the GPU hours compared to InfiFusion* (55 vs 160). This is thanks to our implicit model fusion objective, which replaces token-level KL with sequence-level KL. This strategy preserves probability information while avoiding complex vocabulary alignment processes, making InfiFPO more efficient and scalable.
- InfiFPO consistently outperforms preference optimization baselines. After training on half of the data's preferred responses , SFT improved by 1.62 on average compared to the original model. Then, using the remaining half of the data for preference optimization, InfiFPO outperformed all preference optimization baselines. Compared to SFT-WRPO (the best-performing baseline), InfiFPO showed an average improvement of 0.53 across 11 benchmarks while using about the same amount of GPU hours (58 vs 57). This demonstrates that our InfiFPO can better incorporate source model knowledge to enhance performance without significantly increasing training time compared to existing preference optimization baselines.
Analysis
We conduct two analyses: (1) examining the effectiveness of InfiFPO when combined with other preference optimization objectives; and (2) evaluating how different fusion strategies influence InfiFPO's performance. Due to space limitations, we only report three metrics: Math represents the average results from GSM8K, MATH, and ThmQA; Code represents the average of MBPP and HEval; and All represents the average results across all 11 benchmarks.
Adaptation to Other Preference Optimization Objectives. InfiFPO is fundamentally an improvement on the reference model, making it applicable not only to DPO but also to other DPO variants. To verify the versatility of InfiFPO, we integrated it with IPO and WRPO, creating InfiFPO and InfiFPO respectively.
| Method | Math | Code | All |
|---|---|---|---|
| WRPO | 75.94 | 84.84 | 82.80 |
| InfiFPO_WRPO | 76.31 (+0.4) | 85.20 (+0.2) | 83.32 (+0.5) |
| IPO | 75.29 | 83.93 | 82.38 |
| InfiFPO_IPO | 76.37 (+1.1) | 84.54 (+0.5) | 83.15 (+0.8) |
The table demonstrates InfiFPO's versatility as a general enhancement framework that can be effectively integrated with various preference optimization objectives beyond standard DPO. When integrated with WRPO, InfiFPO delivers modest but consistent gains in mathematical reasoning (+0.4), code generation (+0.2), and overall performance (+0.5). The improvements are more pronounced when combining InfiFPO with IPO, yielding notable enhancements in Math (+1.1) and Code (+0.5) benchmarks, with an overall improvement of +0.8 across all tasks. These results empirically validate that InfiFPO's fusion-based approach provides complementary benefits to existing preference optimization techniques by leveraging diverse source models while maintaining the pivot model's optimization objective.
Different Fusion Strategies. We proposed the max-margin fusion strategy to extract unique information from source models. Additionally, we explored two other fusion strategies: an average-based strategy and a confidence-based strategy. For the average-based strategy, we treat all source models equally, assigning each a weight of 1/. For the confidence-based strategy, we weight source models according to their confidence in the response, measured by sequence probability, meaning models with higher confidence receive greater weights.
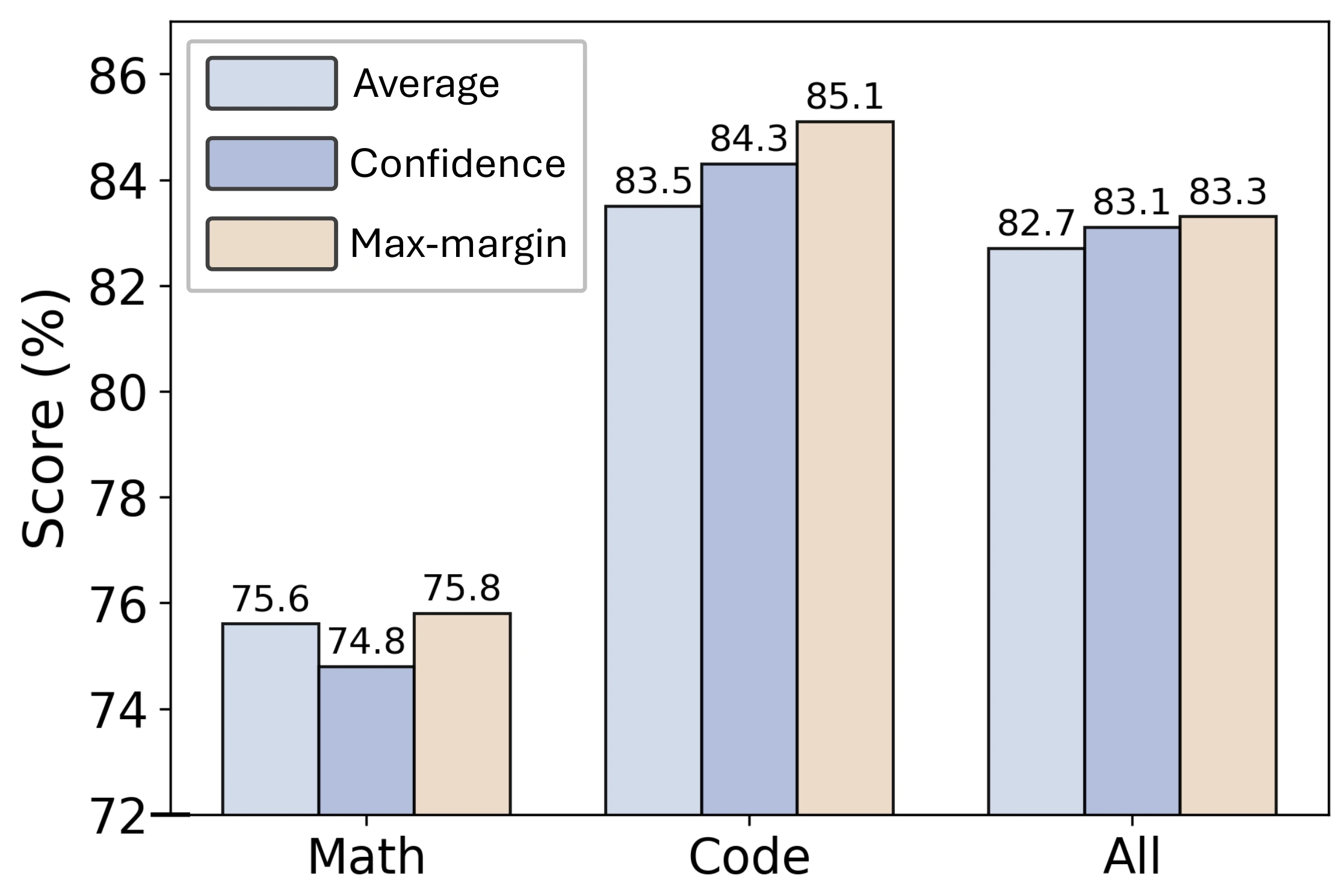
Performance comparison of different fusion strategies. The max-margin strategy consistently outperforms average-based and confidence-based strategies.
We observe that the Confidence-based strategy slightly outperforms the Average-based strategy, likely because it emphasizes high-confidence models during fusion, thus acquiring better information. The max-margin strategy consistently outperforms both the Average-based and Confidence-based strategies, as it focuses on the most distinctive models, thereby learning more unique and complementary information.
Ablation Study
To investigate the effects of different components in InfiFPO, we conducted ablation experiments in two parts: Length Normalization & Probability Clipping, and Number of Source Models.
Length Normalization and Probability Clipping.
| Method | LN | PC | Math | Code | All |
|---|---|---|---|---|---|
| Phi-4 | 72.85 | 79.47 | 79.95 | ||
| InfiFPO | 72.72 (-0.1) | 78.42 (-1.0) | 79.51 (-0.4) | ||
| InfiFPO | ✓ | 75.06 (+2.4) | 83.99 (+4.5) | 82.86 (+2.9) | |
| InfiFPO | ✓ | 74.39 (+1.3) | 81.32 (+1.9) | 81.41 (+1.5) | |
| InfiFPO | ✓ | ✓ | 75.80 (+3.1) | 85.15 (+5.6) | 83.33 (+3.3) |
Without these optimizations, InfiFPO actually underperforms the baseline Phi-4 model. Length Normalization alone provides substantial improvements across all metrics (+2.4 in Math, +4.5 in Code, +2.9 in All), addressing the length bias issue. Similarly, Probability Clipping yields notable gains (+1.3 in Math, +1.9 in Code, +1.5 in All) by preventing source model degradation. The combination of both techniques delivers the strongest performance boost, with significant improvements across all benchmarks (+3.1 in Math, +5.6 in Code, +3.3 in All), confirming their complementary nature in enhancing model capabilities.
Number of Source Models. We conducted experiments on InfiFPO with an increasing number of source models, adding different models one by one for fusion. The experiment started with a single source model, Qwen2.5-Instruct, then gradually added Mistral-Small, Qwen2.5-Coder, Gemma-3-Instruct, and Qwen2.5-Math.
| Num | Math | Code | All |
|---|---|---|---|
| 1 | 74.91 | 81.91 | 81.54 |
| 2 | 75.53 (+0.6) | 82.49 (+0.5) | 82.20 (+0.6) |
| 3 | 75.60 (+0.6) | 83.99 (+2.0) | 82.74 (+1.2) |
| 4 | 75.25 (+0.3) | 85.21 (+3.3) | 83.14 (+1.6) |
| 5 | 75.80 (+0.8) | 85.15 (+3.2) | 83.33 (+1.7) |
The table shows clear performance improvements as the number of source models increases. With each additional model, we observe consistent gains across all metrics, particularly in Code tasks (+3.2 points with 5 models). The diminishing returns after 4-5 models suggest a balance between performance benefits and computational resources when selecting source models for fusion.
Related Work
Preference Optimization. Aligning LLMs with human preferences often relies on RLHF, where a reward model is trained from human comparisons and used in PPO to optimize the policy. While effective, RLHF is resource-intensive and complex to converge. To simplify preference alignment, DPO reformulates the objective as offline learning from preference pairs, removing the need for a reward model and RL. IPO unifies RLHF and DPO under a general preference optimization framework, and proposes a variant that avoids overfitting by using the identity transformation, offering more stable learning in low-data or biased settings. The PAD framework further models preference knowledge as a probability distribution over responses, providing more nuanced supervisory signals for preferences distilling.
Model Fusion. Integrating models aims to combine multiple LLMs into a single model that inherits their respective strengths. While earlier methods like model merging require architectural compatibility, fusion techniques relax such constraints, making them more suitable for heterogeneous models. Knowledge distillation (KD) offers an alternative approach for transferring capabilities across models without requiring structural homogeneity. KD transfers the generalization ability of larger models to smaller ones by leveraging "soft targets"—the output probability distributions (logits) of the teacher model—enabling efficient deployment while preserving performance. However, traditional KD typically assumes that the teacher model is larger than the student and fully covers the target capability space. Moreover, most prior work has focused on the single teacher setting, limiting its flexibility in multi-teacher scenarios. FuseLLM introduced LLM fusion, showing gains in reasoning and code tasks. Later works extended this idea across domains but struggled with structural mismatches. To address this, pairwise fusion sequentially integrates models into the pivot model, and InfiFusion improved it via adaptive merging and unified output aggregation. The most explicit fusion approaches operate at the token level and face vocabulary alignment issues. WRPO mitigates this by shifting fusion to the sequence level using reinforcement learning, enabling implicit fusion without vocabulary conflicts. However, WRPO has two major limitations: it discards probabilistic outputs using only response-level supervision, and focuses solely on preferred responses while ignoring contrastive signals from dispreferred ones, resulting in only partial leverage of source model capabilities.
Conclusion
We introduce InfiFPO, a novel framework that enables model fusion during the preference alignment phase by replacing the reference model in DPO with a fused sequence-level distribution over multiple source models. Unlike prior work, InfiFPO leverages full-sequence probabilities rather than token-level outputs, thereby avoiding vocabulary alignment issues across heterogeneous models while preserving rich preference signals.
To make this optimization practical and efficient, we derive an offline training objective from a sequence-KL constrained RLHF formulation, termed FuseRLHF. We further enhance stability through three key strategies: length normalization to mitigate sequence bias, probability clipping to suppress noisy gradients, and max-margin fusion to prioritize diverse and informative sources.
Experiments across 11 benchmarks demonstrate that InfiFPO consistently outperforms strong baselines in both model capability and alignment quality. Our results highlight that preference optimization not only accommodates but can significantly benefit from principled model fusion, offering a robust and scalable path to integrating diverse LLMs.
Limitation
Despite InfiFPO demonstrating significant empirical performance, it still relies on existing preference optimization methods such as DPO. More rigorous theoretical analysis is needed to better understand InfiFPO's fusion mechanisms and further strengthen its theoretical foundation. Additionally, due to computational resource constraints, we only selected five mainstream open-source LLMs as source models for our experiments, which cannot represent the SOTA performance of current advanced LLMs. Experiments with larger-scale models and datasets remain unexplored.
BibTeX
@misc{gu-2025-infifpo,
title={InfiFPO: Implicit Model Fusion via Preference Optimization in Large Language Models},
author={Yanggan Gu and Zhaoyi Yan and Yuanyi Wang and Yiming Zhang and Qi Zhou and Fei Wu and Hongxia Yang},
year={2025},
eprint={2505.13878},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2505.13878},
}