BPDQ: Bit-Plane Decomposition Quantization on a Variable Grid for Large Language Models
ABSTRACT
Large language model inference is often bounded by memory footprint and memory bandwidth in resource-constrained deployments, making quantization a fundamental technique for efficient serving. While post-training quantization maintains high fidelity at 4-bit, it deteriorates at 2-3 bits. BPDQ constructs a variable quantization grid via bit-planes and scalar coefficients, then iteratively refines them with approximate second-order information and progressive error compensation to minimize output discrepancy. In the 2-bit regime, BPDQ enables serving Qwen2.5-72B on a single RTX 3090 with 83.85% GSM8K accuracy, compared with 90.83% at 16-bit.

Fixed grids enforce shape invariance, while BPDQ constructs a variable grid per group using bit-plane coefficients.
Abstract
Large language model (LLM) inference is often bounded by memory footprint and memory bandwidth in resource-constrained deployments, making quantization a fundamental technique for efficient serving. While post-training quantization (PTQ) maintains high fidelity at 4-bit, it deteriorates at 2-3 bits.
Existing methods enforce a shape-invariant quantization grid, such as the fixed uniform intervals of UINT2, for each group. This severely restricts the feasible set for error minimization. BPDQ addresses this with Bit-Plane Decomposition Quantization, constructing a variable quantization grid through bit-planes and scalar coefficients. It iteratively refines both components using approximate second-order information and progressive error compensation to minimize output discrepancy.
In the 2-bit regime, BPDQ enables serving Qwen2.5-72B on a single RTX 3090 with 83.85% GSM8K accuracy, compared with 90.83% at 16-bit.
Introduction
Quantization is a practical route to reducing memory footprint and memory bandwidth bottlenecks in LLM inference. Quantization-aware training can perform well, but the training cost is high. Quantization-aware fine-tuning improves low-bit performance but requires a two-stage pipeline. Distribution-aware PTQ methods can reduce outlier-induced distortion, while optimization-based methods such as GPTQ minimize output discrepancy with an output-aligned objective.
The difficulty appears when precision is pushed down to 2-3 bits. A 2-bit representation provides only four distinct values, and fixed grids force every group to share the same relative spacing pattern after scaling. Uniform grids use levels like scale * {0, 1, 2, 3}; fixed non-uniform grids use scale * {a0, a1, a2, a3}. Although the scale can differ by group, the shape of the grid is shared.
BPDQ's central claim is that the low-bit failure of optimization-based PTQ is primarily caused by this rigid feasible set, not by the optimization objective itself. BPDQ relaxes the grid by constructing group-specific values with bit-plane coefficients, allowing each group to adapt its relative level spacing.
The paper contributes:
- Insight: fixed-grid shape invariance is a fundamental constraint on optimization-based PTQ in low-bit regimes.
- Methodology: BPDQ decomposes weights into bit-planes, fits scalar coefficients, and refines them under Hessian-induced geometry.
- Performance: experiments show strong fidelity across language understanding, reasoning, and long-context benchmarks, while preserving a hardware-friendly bit-plane format.
Related Work
Low-bit Quantization for LLMs
Extreme compression methods include QAT approaches that optimize in Boolean domains or use factorized representations, but these can be costly to train. PTQ methods based on vector quantization map weights to codebooks and can preserve strong fidelity, but they suffer from heavy quantization overhead. Distribution-aware methods use hybrid formats or mixed precision to protect salient weights, often at the cost of irregular memory access.
Recent bit-plane and ternary decomposition methods are attractive for accelerator-friendly arithmetic, but many rely on progressive residual correction or fine-tuning and do not directly optimize a rigorous output-aligned PTQ objective.
Optimization-based PTQ
Optimization-based PTQ minimizes output discrepancy, usually of the form:
This line of work connects to second-order sensitivity analyses, Optimal Brain Compression, GPTQ, and geometric interpretations of GPTQ as nearest-plane search under a Hessian-induced metric. These methods have a strong objective, but the fixed quantization grid can still restrict the solution space too aggressively at 2-3 bits. BPDQ keeps the optimization-based PTQ perspective and expands the feasible set with variable grids.
Methodology
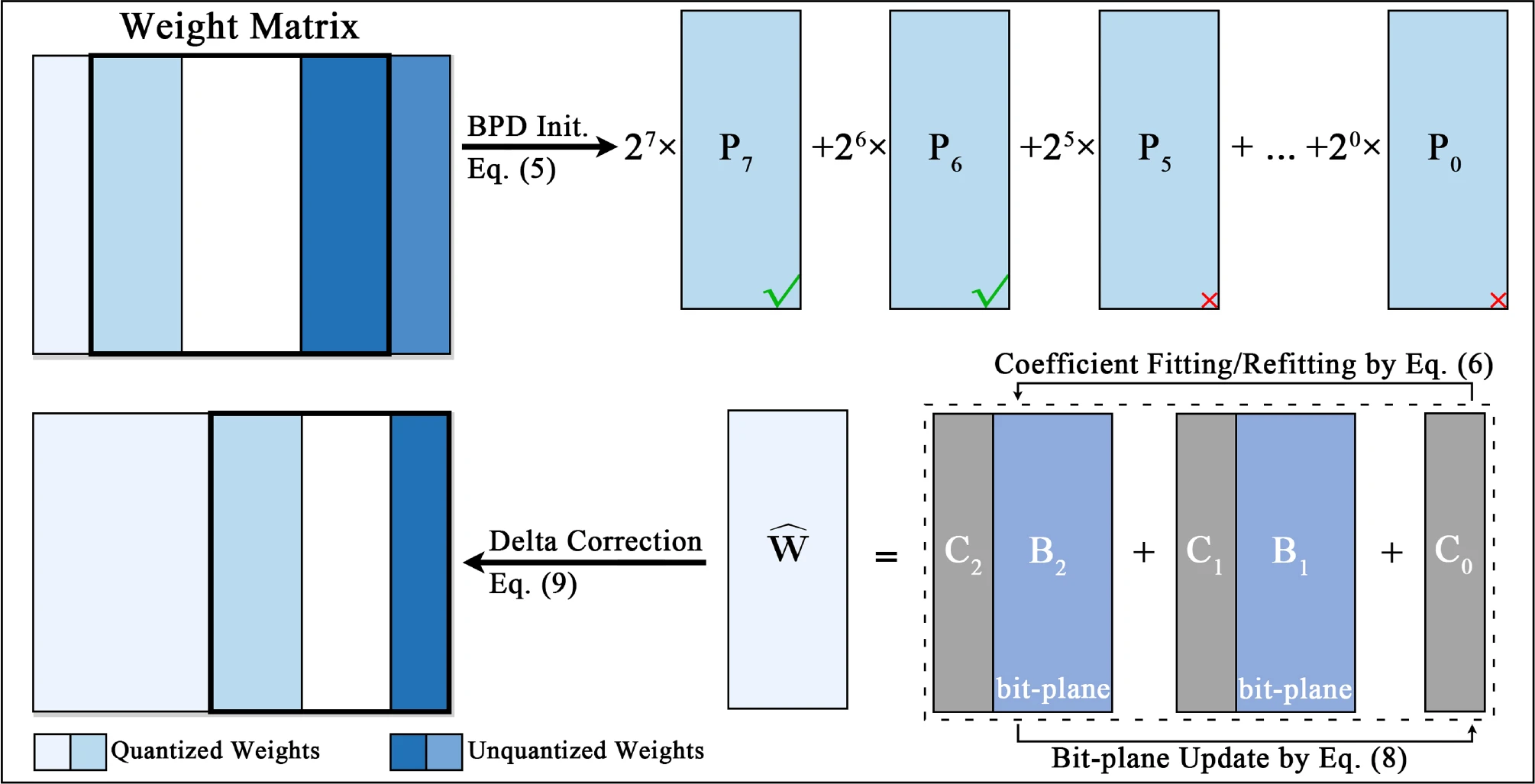
Overview of the 2-bit BPDQ quantization procedure.
BPDQ follows the output-aligned PTQ objective while replacing the fixed quantization grid with a variable grid. It initializes through bit-plane decomposition and closed-form scalar coefficient fitting, then iteratively refines the grid using column-wise bit-plane updates, group-wise coefficient refitting, and Hessian-aware error compensation.
The quantized weight is parameterized as:
Here, is the -th bit-plane, is a group-wise scale coefficient, is a group-wise bias coefficient, and repeats group coefficients along the input dimension.
Optimization Objective
For a linear layer with weight and calibration activations , BPDQ follows the PTQ objective:
Equivalently:
where is the approximate Hessian metric induced by calibration data.
Hessian-aware Error Compensation
Following GPTQ-style optimization, BPDQ uses the Cholesky factorization and propagates quantization error through triangular updates. For the -th column:
The working weights are updated by:
This keeps the sequential update aligned with the Hessian-induced objective.
Variable Grid Initialization
For a group , BPDQ first applies an affine quantizer to obtain an unsigned 8-bit integer matrix:
The most significant bit-planes are selected as the initial low-bit representation. These planes capture the dominant magnitude information, while discarded low-order planes introduce a small truncation error.
Scalar Coefficient Fitting
With bit-planes fixed, BPDQ fits scalar coefficients in closed form under Hessian-induced geometry. For each row, it solves a weighted least-squares problem:
This produces group-specific coefficients and therefore group-specific quantization level spacing.
Iterative Refinement
For each group, BPDQ alternates between bit-plane update and coefficient refitting. The paper uses 10 iterations in all experiments and keeps the iterate that minimizes the group-wise propagation error.
With fixed coefficients, each row and column enumerates all candidate bit vectors:
The selected bit vector minimizes:
After the bit-plane update, coefficients are refit. Because refitting changes the quantized block, BPDQ applies a delta correction:
This synchronizes the propagation state and keeps later columns consistent with the same output-aligned objective.
Experiments
Setup
Experiments cover Qwen-3 models from 0.6B to 32B, Qwen-2.5 7B and 72B, and Ministral-3 3B and 8B. The evaluation uses lm-evaluation-harness on WikiText-2, GSM8K, MATH500, ARC-C, BoolQ, HellaSwag, MMLU, and LongBench.
BPDQ is implemented in the GPTQModel library. GPTQ and AWQ are used as fixed-grid baselines, and the paper also compares with AnyBCQ as a bit-plane method and VPTQ as a vector quantization method. All methods use asymmetric quantization calibrated on 1024 C4 samples. BPDQ uses larger group sizes than GPTQ/AWQ to offset the storage overhead of per-bit-plane scalar coefficients.
Main Results on Large Models
Table 1 in the paper evaluates Ministral3-8B, Qwen3-32B, and Qwen2.5-72B across seven benchmarks. The most deployment-relevant result is the Qwen2.5-72B 2-bit setting:
| Model / Method | BPW | Wiki2 ↓ | GSM8K ↑ | MATH500 ↑ | ARC-C ↑ | BoolQ ↑ | HellaS ↑ | MMLU ↑ |
|---|---|---|---|---|---|---|---|---|
| Qwen2.5-72B 16-bit | 16 | 4.72 | 90.83% | 55.80% | 63.05% | 90.49% | 87.35% | 83.38% |
| GPTQ-W2-G32 | 2.56 | 10.01 | 63.46% | 28.40% | 53.16% | 86.21% | 78.60% | 69.59% |
| AWQ-W2-G32 | 2.56 | 4.0E+7 | 0.00% | 0.00% | 41.47% | 68.75% | 58.09% | 56.94% |
| BPDQ-W2-G64 | 2.75 | 8.35 | 87.72% | 51.20% | 59.47% | 90.37% | 82.71% | 77.14% |
| BPDQ-W2-G128 | 2.38 | 8.66 | 86.13% | 47.60% | 60.75% | 90.06% | 82.20% | 76.73% |
| BPDQ-W2-G256 | 2.19 | 8.94 | 83.85% | 39.40% | 60.24% | 89.72% | 81.69% | 75.89% |
In the W2-G256 setting, BPDQ compresses Qwen2.5-72B enough to run on a single RTX 3090 with 22.69 GB VRAM while retaining 83.85% GSM8K accuracy, or 92.32% of the 16-bit baseline.
Comparison on Qwen2.5-7B
On Qwen2.5-7B, BPDQ is compared against GPTQ, AWQ, AnyBCQ, and VPTQ:
| Method | Size (GB) | Wiki2 ↓ | GSM8K ↑ | MATH500 ↑ | ARC-C ↑ | BoolQ ↑ | HellaS ↑ | MMLU ↑ |
|---|---|---|---|---|---|---|---|---|
| Qwen2.5-7B | 14.19 | 9.42 | 75.97% | 46.00% | 55.29% | 86.39% | 80.44% | 71.76% |
| GPTQ-W2-G64 | 3.77 | 42.59 | 0.00% | 1.40% | 29.27% | 59.14% | 58.51% | 27.10% |
| AWQ-W2-G64 | 3.76 | N/A | 0.00% | 0.00% | 25.17% | 38.81% | 32.14% | 26.03% |
| AnyBCQ-W2-G128 | 3.92 | 22.57 | 4.47% | 5.80% | 44.54% | 77.52% | 65.83% | 48.54% |
| BPDQ-W2-G128 | 3.84 | 16.85 | 35.48% | 10.40% | 45.90% | 84.62% | 68.76% | 57.46% |
VPTQ achieves strong accuracy in some 2-bit settings, but its quantization overhead is substantially higher. BPDQ is designed to keep a bit-plane representation that is more hardware friendly.
Efficiency and Outlier Preservation
The paper also profiles system efficiency and activation outlier statistics on Qwen2.5-7B:
| Model | Cost (min) | VRAM (GB) | Latency (ms) | DiagR P95 | ΔDiagR | Cnt10 | ΔCnt10 |
|---|---|---|---|---|---|---|---|
| Qwen2.5-7B | N/A | 14.19 | 14.42 | 3.01E4 | N/A | 4.32E4 | N/A |
| GPTQ-W2-G32 | 17 | 3.77 | 33.91 | 2.02E4 | -32.89% | 3.30E4 | -23.61% |
| VPTQ-W2 | 4x170 | 4.32 | 18.24 | 2.68E4 | -10.96% | 4.44E4 | +2.78% |
| BPDQ-W2-G64 | 40 | 3.86 | 18.09 | 2.86E4 | -4.98% | 4.24E4 | -1.85% |
BPDQ requires roughly 3x the quantization time of GPTQ due to iterative refinement, but it is far faster than VPTQ's reported overhead. For inference, the bit-plane look-up table kernel enables efficient per-token decoding for batch-size-1 interactive generation. The activation statistics show that GPTQ-W2 heavily suppresses outlier features, while BPDQ better preserves them under 2-bit quantization.
Long-Context Evaluation
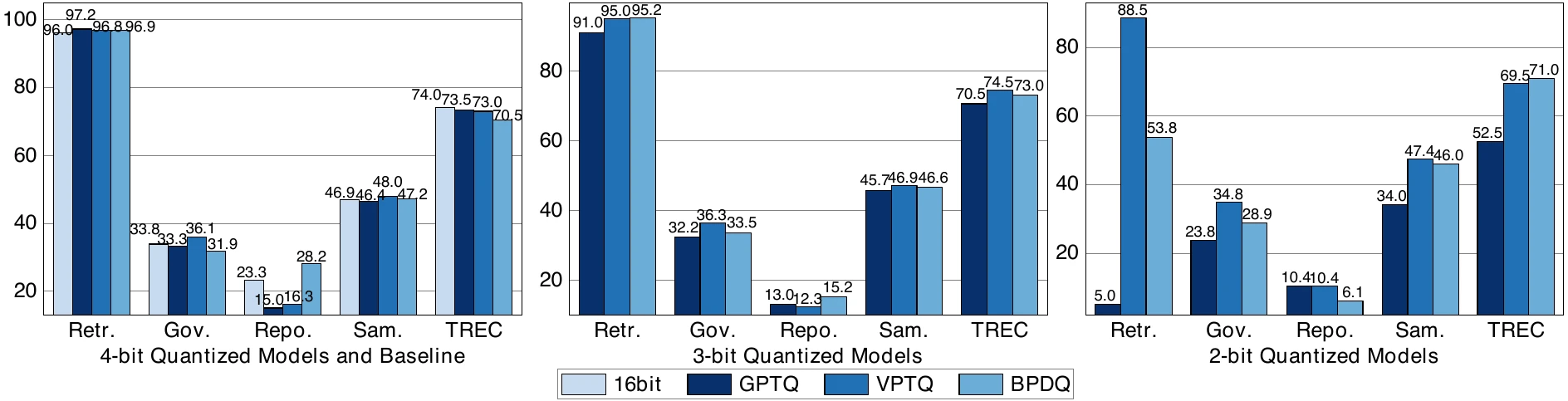
LongBench performance comparison on Qwen2.5-7B.
LongBench evaluation covers retrieval, summarization, code completion, and classification tasks. At 3-4 bits, quantized models are generally robust. At 2 bits, retrieval becomes a stress test: GPTQ drops sharply, while BPDQ sustains substantially stronger performance. VPTQ can be more resilient in some cases, but with a much higher quantization cost.
Theoretical Analysis
The appendix frames optimization-based PTQ as a nearest-point projection under a Hessian-induced metric:
This makes the quantization quality depend on the richness of the feasible set .
For 2-bit precision, a fixed uniform grid can only represent:
BPDQ represents:
By choosing and , BPDQ exactly reproduces the standard UINT2 grid. But because and are independent, BPDQ can also represent non-uniform grids that no single scale can express. The appendix further shows that this extra degree of freedom yields a non-empty open set of weight vectors where variable-grid quantization has strictly lower error than fixed-template quantization.
The consistency appendix proves three parts:
- Coefficient fitting is equivalent to minimizing the local contribution to the Hessian-induced objective.
- Bit-plane update minimizes the relevant column-wise error term under fixed coefficients.
- Delta correction preserves the propagation invariant after coefficient refitting.
Limitations and Future Work
BPDQ still leaves a fidelity gap compared with vector quantization in some settings, though vector quantization often has higher overhead and less straightforward hardware support. Future work could combine BPDQ with rotation techniques or enhanced sequential solvers such as Qronos.
The bit-plane structure is naturally suited to FPGA and ASIC deployment because binary planes can replace expensive floating-point multiplications with simple additions. BPDQ also suggests a path toward mixed- and multi-precision serving: instead of supporting multiple data types, a system could allocate more or fewer bit-planes and serve different accuracy-latency trade-offs from one on-device model.
Conclusion
BPDQ relaxes the shape-invariant grid constraint that limits optimization-based PTQ in low-bit regimes. By constructing variable grids from bit-planes and scalar coefficients, then refining them within Hessian-induced geometry, BPDQ enables high-fidelity 2-bit inference for large language models while preserving a hardware-friendly format.
BibTeX
@misc{chen-2026-bpdq,
title={BPDQ: Bit-Plane Decomposition Quantization on a Variable Grid for Large Language Models},
author={Junyu Chen and Jungang Li and Jing Xiong and Wenjie Wang and Qingyao Yang and He Xiao and Zhen Li and Taiqiang Wu and Mengzhao Chen and Zhen Peng and Chaofan Tao and Long Shi and Hongxia Yang and Ngai Wong},
year={2026},
eprint={2602.04163},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2602.04163},
}